Gemini 3 Flash ist das neueste KI-Modell von Google DeepMind/Gemini, das entwickelt wurde, um bahnbrechende Schlussfolgerungen und multimodale Fähigkeiten zu liefern und gleichzeitig Latenzzeiten und Kosten drastisch zu reduzieren. Als schnellerer und effizienterer Nachfolger von Gemini 2.5 Flash stellt es eine bedeutende Weiterentwicklung im Bereich der praktischen KI-Anwendung dar, von Chat-Assistenten für Verbraucher bis hin zu Entwickler-APIs und Unternehmenssystemen.
In diesem Artikel untersuchen wir, was Gemini 3 Flash ist, wie es im Vergleich zu Gemini 2.5 Flash abschneidet, seine Benchmarks und Leistung, reale Anwendungen und warum es für KI-Entwickler, Unternehmen und Endnutzer gleichermaßen wichtig ist.
Was ist Gemini 3 Flash?
Gemini 3 Flash ist das neueste „Flash”-KI-Modell von Google, das sich durch schnelle Schlussfolgerungen, vielseitiges multimodales Verständnis und produktionsreife Effizienz auszeichnet. Gemini 3 Flash basiert auf derselben grundlegenden Architektur wie Gemini 3 Pro und bietet starke Schlussfolgerungs- und Codierungsfähigkeiten zu einem Bruchteil der Kosten und mit einer deutlich höheren Reaktionsfähigkeit.
Laut Google zeigt Gemini 3 Flash, dass Modelle nicht zugunsten der Geschwindigkeit an Intelligenz einbüßen müssen: Es erzielt wettbewerbsfähige Ergebnisse bei Benchmarks für Schlussfolgerungen auf Doktorandenebene und multimodale Schlussfolgerungen und arbeitet dabei wesentlich schneller als seine Vorgänger.
Wichtige Positionierungspunkte:
- Geschwindigkeit – Entwickelt für geringe Latenz und hohen Durchsatz.
- Kosteneffizienz – Geringere Betriebskosten bei großflächiger Nutzung.
- Leistung – Starke multimodale Verständnis-, Schlussfolgerungs- und Codierungs-Benchmarks.
- Multimodale Fähigkeiten – Verarbeitet Text, Bilder, Audio und mehr in einem einheitlichen Stack.
Gemini 3 Flash hat Gemini 2.5 Flash als Standardmodell in der Gemini-App abgelöst und ist über APIs, Google AI Studio, Vertex AI und Entwicklertools weitreichend zugänglich.
Gemini 3 Flash vs. Gemini 2.5 Flash: Die Entwicklung der Flash-Modelle
Architektonische Ziele
Sowohl Gemini 3 Flash als auch Gemini 2.5 Flash gehören zur „Flash”-Familie der KI-Modelle von Google, bei denen ein ausgewogenes Verhältnis zwischen Geschwindigkeit, Kosten und Intelligenz im Vordergrund steht. Gemini 3 Flash erweitert diese Philosophie jedoch um tiefgreifendere Schlussfolgerungen und robuste multimodale Verarbeitung in Bereichen, in denen Gemini 2.5 Flash Einschränkungen aufwies.
| Funktion | Gemini 3 Flash | Gemini 2.5 Flash |
| Veröffentlichung | Dec 2025 | Aktualisierungen für 2025 (Vorschau und Verbesserungen) |
| Geschwindigkeit | ~3× schneller als 2.5 Pro in Benchmarks | Flash-Linie: auf Geschwindigkeit optimiert, aber schwächeres Schlussfolgerungsvermögen |
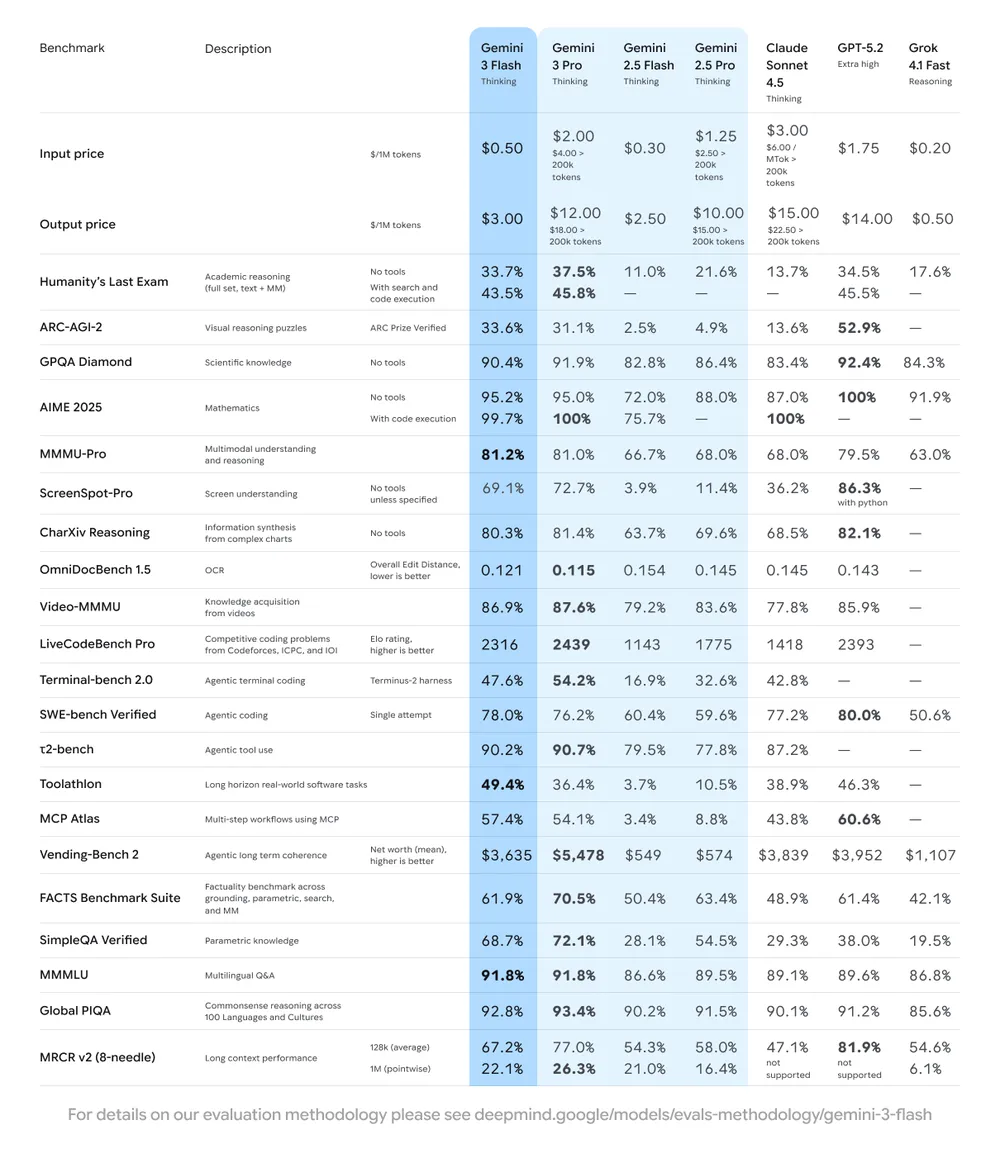
| Begründung | Grenzwert (GPQA Diamond: 90,4 %) | Deutlich niedrigere Ergebnisse bei akademischen Denkaufgaben |
| Codierung / Agenten | SWE-Bench Verifiziert: ~78 % | Geringere agentiale Kodierungsleistung |
| Multimodalität | Starkes multimodales Denken (MMMU Pro: ~81,2 %) | Weniger robuste multimodale Fähigkeiten |
| Kosten pro Token | ~0,50 $ Input / 3 $ Output | Im Allgemeinen günstiger pro Token, aber insgesamt weniger effizient |
| Token-Effizienz | Im Durchschnitt ~30 % weniger im Vergleich zu 2.5 Pro | Grundlegende Token-Effizienz |
Diese Tabelle zeigt, wie Gemini 3 Flash im Vergleich zu Gemini 2.5 Flash und 2.5 Pro die Kompromisse zwischen Geschwindigkeit, Kosten und Intelligenz neu kalibriert.
Gemini 3 Flash ist schneller und klarer als 2.5 Pro.
Benchmark-Leistung und Geschwindigkeit
Bildnachweis: Google
Argumentation & Wissen
Gemini 3 Flash erreicht Spitzenleistungen bei der Bewertung von Schlussfolgerungen und Wissen:
- GPQA Diamond: ~90,4 % – ein Benchmark für logisches Denken auf Doktorandenebene.
- Humanity’s Last Exam: ~33,7 % (ohne Hilfsmittel), was auf solides Allgemeinwissen hinweist.
Mit diesen Werten liegt es vor vielen früheren Flash- und Pro-Modellen und kann mit den besten KI-Modellen auf dem Markt mithalten.
Multimodales Verständnis
Im MMMU Pro-Benchmark, der das Schlussfolgern über verschiedene Modalitäten hinweg (Text, Bilder usw.) testet, erreicht Gemini 3 Flash eine Punktzahl von ~81,2 % und demonstriert damit ein starkes multimodales Schlussfolgern, das mit schwereren Modellen konkurrieren kann.
Codierung und Agent-Fähigkeiten
Das Modell zeichnet sich auch bei Codierungsaufgaben aus:
- SWE-Bench-verifiziert: ~78 %, übertrifft die entsprechenden Werte von Gemini 2.5 Pro und sogar einige größere Varianten.
Dies deutet darauf hin, dass Gemini 3 Flash nicht nur für allgemeine KI-Interaktionen geeignet ist, sondern auch für agentenbasierte Arbeitsabläufe und programmatische Aufgaben, bei denen Effizienz und geringe Latenz eine Rolle spielen.
Token-Effizienz und Latenz
- Verbraucht bei typischen Workloads durchschnittlich ~30 % weniger Tokens als Gemini 2.5 Pro.
- Bis zu ~3× schnellere Inferenzleistung im Vergleich zu 2.5 Pro.
Diese Kombination aus Effizienz und Geschwindigkeit ermöglicht Kosteneinsparungen und reaktionsschnelle Interaktionen sowohl für Benutzer als auch für Entwickler.
Preisgestaltung und Kosteneffizienz
Die Preisstrategie von Gemini 3 Flash ist darauf ausgelegt, eine breite Akzeptanz und Einführung zu erleichtern:
- Eingabetoken: ~0,50 $ pro Million
- Ausgabetoken: ~3,00 $ pro Million
- Audioeingabe (falls verwendet): ~1,00 $ pro Million
Trotz eines etwas höheren Token-Preises als bei älteren Flash-Modellen führt die verbesserte Effizienz des Gemini 3 Flash (30 % weniger Token) oft zu niedrigeren Gesamtkosten für Routineaufgaben. Darüber hinaus können Kontext-Caching und Batch-API-Rabatte die Betriebskosten weiter senken.
Diese kostengünstige Leistung macht Gemini 3 Flash attraktiv für hochfrequente Anwendungen wie Dialogagenten, Echtzeit-Codierungsassistenten und interaktive KI-Funktionen, die in Produkte integriert sind.
Wo Gemini 3 Flash verwendet wird
Standard in der Gemini-App und KI-Suche
Gemini 3 Flash hat Gemini 2.5 Flash als Standardmodell in der Gemini-App abgelöst und unterstützt den KI-Modus in der Google-Suche, wodurch Nutzer schnellere und intelligentere Antworten erhalten.
Das bedeutet, dass normale Nutzer bei routinemäßigen KI-Interaktionen von fortschrittlichen Schlussfolgerungen und multimodaler Unterstützung profitieren, ohne Einstellungen anpassen oder manuell ein Modell auswählen zu müssen.
Entwicklerzugang (APIs und Plattformen)
Entwickler und Unternehmen können Gemini 3 Flash über folgende Wege in Anwendungen und Workflows integrieren:
- Google AI Studio
- Gemini API
- Vertex AI
- Gemini CLI
- Integrationen mit Tools wie Antigravity und Android Studio
Diese breite Verfügbarkeit stellt sicher, dass sowohl Entwickler als auch Unternehmen das Modell in Produktionssystemen, agentenbasierten Workflows und intelligenten Benutzeroberflächen nutzen können.
Anwendungen in der Praxis
KI-Assistenten und virtuelle Agenten
Dank seiner schnellen Reaktionszeiten und seiner umfangreichen Schlussfolgerungsfähigkeiten eignet sich Gemini 3 Flash ideal für Echtzeit-Konversationsagenten, sei es in Kundensupport-Bots, digitalen Assistenten oder integrierten Sucherlebnissen.
Virtuelle Agenten können beispielsweise Gemini 3 Flash nutzen, um komplexe Benutzeranfragen zu analysieren, kontextbezogene Antworten zu geben und Vorschläge für die nächsten Schritte mit minimaler Latenz zu generieren.
Entwicklertools und agentenbasierte Workflows
Mit starken Coding-Benchmark-Ergebnissen eignet sich Gemini 3 Flash für agentenbasierte Coding-Tools, die Entwicklern beim Generieren, Refaktorisieren und Debuggen von Code helfen. Seine schnelle Inferenz und Schlussfolgerung unterstützen auch Entwicklerassistenten mit geringer Latenz, die in IDEs oder Cloud-Workflows eingebettet sind.
Multimodale Analyse und Inhaltsverständnis
Da Gemini 3 Flash sich durch multimodales Schlussfolgern auszeichnet, werden Anwendungen wie Bildanalyse, Zusammenfassung von Videoinhalten und Multimedia-Extraktion selbst in groß angelegten Zeitachsen möglich.
Interaktive KI-Erlebnisse
Von interaktiven Lerntools bis hin zur Echtzeit-Inhaltsplanung – die Fähigkeit des Modells, multimodale Eingaben wie Audio, Text und Bilder zu verstehen und zu synthetisieren, ermöglicht kreative neue Benutzererlebnisse, die sich natürlich und reaktionsschnell anfühlen.
Warum Gemini 3 Flash im Jahr 2025 und darüber hinaus wichtig ist
Gemini 3 Flash steht für einen allgemeinen Trend in der Branche: Effizienz ohne Einbußen bei der Intelligenz. Anstatt immer größere und teurere Modelle auf den Markt zu bringen, legt diese neue Generation Wert auf ein gutes Preis-Leistungs-Verhältnis und praktische Anwendbarkeit.
Die wichtigsten Gründe, warum Gemini 3 Flash so wirkungsvoll ist:
- Geringe Latenz für Echtzeitanwendungen, wodurch es sich für Verbraucher- und Unternehmensanwendungen eignet.
- Kosteneffizienz, die eine nachhaltige Skalierung für Produkte und Dienstleistungen ermöglicht.
- Benchmark-Leistung, die in vielen Bereichen mit leistungsstarken KI-Modellen konkurrieren kann.
- Multimodale Intelligenz, die über reine Textinteraktionen hinaus reichhaltigere Interaktionen unterstützt.
Durch die Neudefinition, wie fortschrittliche KI in großem Maßstab bereitgestellt werden kann, beeinflusst Gemini 3 Flash Produktdesignentscheidungen und senkt die Hürden für die großflächige Einführung von KI-Technologie.
Fazit: Ein neuer Standard in Sachen KI-Leistung und Effizienz
Gemini 3 Flash verkörpert einen entscheidenden Wandel in der Entwicklung von KI-Modellen, bei dem Geschwindigkeit, Kosten und Intelligenz nicht mehr als sich gegenseitig ausschließend betrachtet werden. Es bietet bahnbrechende Schlussfolgerungen, multimodales Verständnis und entwicklerfreundliche Leistung in einem Umfang, der sowohl zugänglich als auch praktisch ist.
Ob zur Unterstützung alltäglicher KI-Assistenten in Apps und Suchmaschinen oder zur Ermöglichung komplexer agentenbasierter Workflows und multimodaler Anwendungen – Gemini 3 Flash setzt neue Maßstäbe für effiziente, praxisnahe KI-Leistung im Jahr 2025 und darüber hinaus. Sein Erfolg unterstreicht die wachsende Bedeutung der Wirtschaftlichkeit pro Token und des multimodalen Denkens in der nächsten Welle der KI-Innovation.
FAQs
Was ist Gemini 3 Flash?
Gemini 3 Flash ist das neueste Hochgeschwindigkeits-KI-Modell von Google, das starke Schlussfolgerungsfähigkeiten, multimodales Verständnis und kosteneffiziente Leistung vereint.
Wie schneidet Gemini 3 Flash im Vergleich zu Gemini 2.5 Flash ab?
Es übertrifft Gemini 2.5 Flash mit höheren Benchmark-Ergebnissen, besserer Schlussfolgerungsfähigkeit, stärkeren multimodalen Fähigkeiten und schnelleren Reaktionszeiten.
In welchen Benchmarks schneidet Gemini 3 Flash besonders gut ab?
Gemini 3 Flash erreicht ~90,4 % bei GPQA Diamond (Logik), ~81,2 % bei MMMU Pro (multimodal) und ~78 % bei SWE-bench Verified (Codierung).
Wo kann ich Gemini 3 Flash verwenden?
Es ist das Standardmodell in der Gemini-App und über Google AI Studio, Vertex AI, die Gemini-API und Entwicklertools wie Gemini CLI verfügbar.
Ist Gemini 3 Flash günstiger als frühere Modelle?
Ja. Obwohl die Token-Preise ähnlich oder höher sein können, bedeutet seine verbesserte Effizienz im Vergleich zu schwereren Modellen wie Gemini 2.5 Pro oder Gemini 3 Pro insgesamt Kosteneinsparungen.
Unterstützt Gemini 3 Flash multimodale Eingaben?
Ja – es verarbeitet Text, Bilder und Audio als Eingaben und kann für interaktive und multimodale Anwendungen verwendet werden.