GPT-5.2-Codex ist das neueste agentenbasierte Codierungsmodell von OpenAI, das speziell für komplexe, reale Softwareentwicklungs- und Cybersicherheitsaufgaben entwickelt wurde. GPT-5.2-Codex basiert auf der GPT-5.2-Architektur und wurde für Codierungs-Workflows weiter optimiert. Es stellt einen bedeutenden Fortschritt bei großen Sprachmodellen dar, die speziell für den Einsatz durch professionelle Entwickler zugeschnitten sind. Seine Veröffentlichung unterstreicht, wie sich KI von einfachen Tools für Code-Vorschläge zu vollwertigen Entwicklungspartnern entwickelt, die in der Lage sind, langwierige, mehrstufige Engineering-Aufgaben zu bewältigen.
Dieser Artikel bietet eine eingehende Analyse von GPT-5.2-Codex, untersucht, wie es sich von konkurrierenden Tools wie Claude Code unterscheidet, und gibt Entwicklern und Entscheidungsträgern praktische Einblicke in reale Anwendungen, Stärken, Einschränkungen und Überlegungen zur Einführung.
Was ist GPT-5.2-Codex?
GPT-5.2-Codex ist das bislang fortschrittlichste agentenbasierte Codierungsmodell von OpenAI. Es erweitert die allgemeine Intelligenz von GPT-5.2 um verbesserte Funktionen, die speziell auf Softwareentwicklung und defensive Cybersicherheit zugeschnitten sind. Im Gegensatz zu generischen GPT-Modellen, die Texte auf der Grundlage von Mustern generieren, ist GPT-5.2-Codex darauf ausgelegt, Codebasen zu verstehen, mehrstufige Implementierungen zu planen, Kontext auf lang andauernde Aufgaben anzuwenden und komplexe Arbeitsabläufe mit realen Tools auszuführen.
Bei der Markteinführung:
- Es unterstützt die Kontextverdichtung und hilft dem Modell dabei, über lange Sequenzen und große Repositorys hinweg relevant zu bleiben.
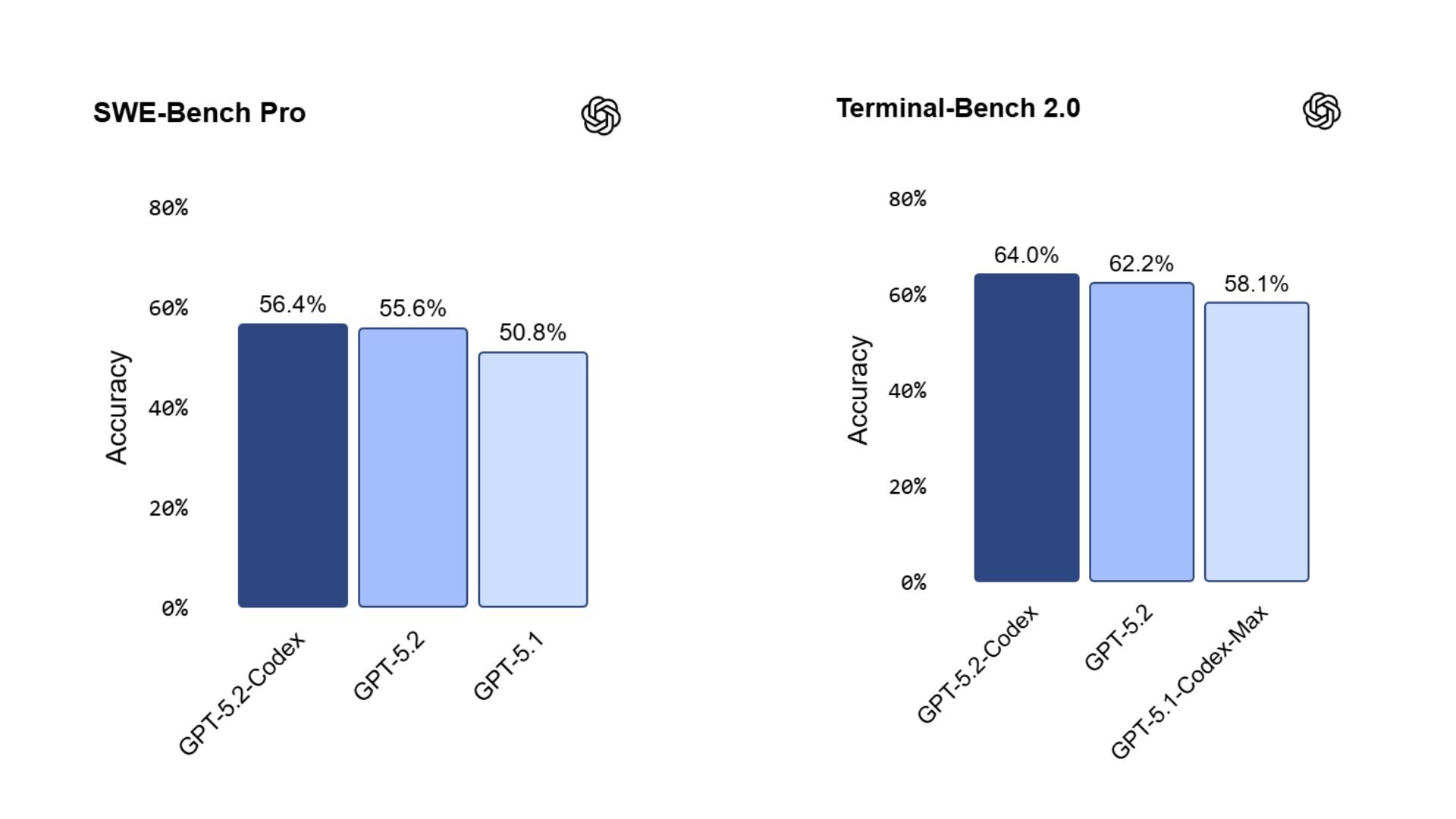
- Es liefert eine verbesserte Leistung bei wichtigen technischen Benchmarks wie SWE-Bench Pro und Terminal-Bench 2.0 und demonstriert damit eine starke Codierungskompetenz in der Praxis.
- Es verfügt über verbesserte Cybersicherheitsfunktionen, wodurch es sich für Schwachstellenanalysen und defensive Forschung eignet.
Zunächst nur für zahlende ChatGPT-Nutzer verfügbar, wird nun ein breiterer API-Zugang mit Sicherheitskontrollen und vertrauenswürdigem Zugang für Forschungsteams eingeführt.
GPT-5.2-Codex vs. GPT-5.2 vs. GPT-5.1-Codex-Max: Eine CTF-Leistungszeitleiste
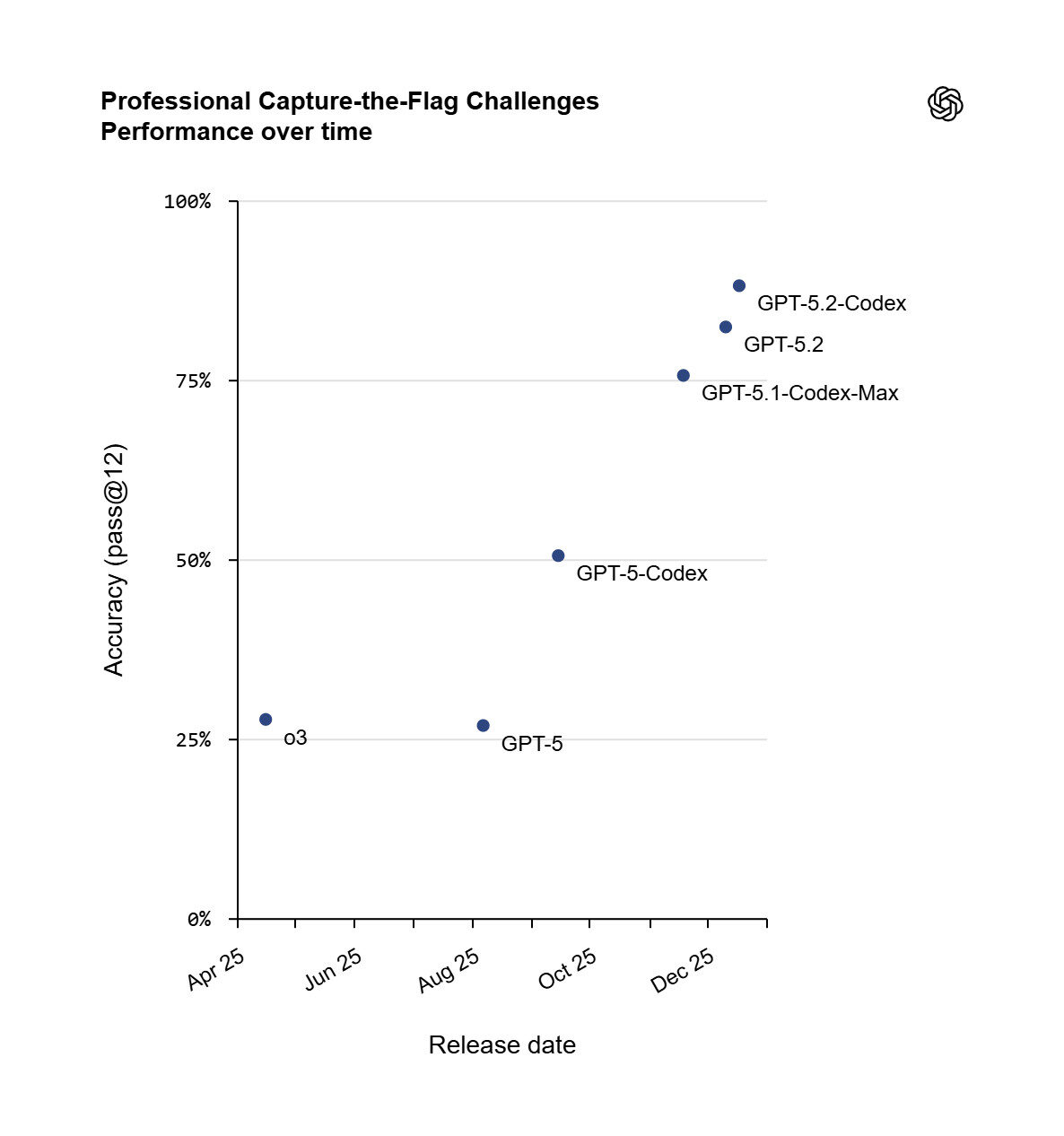
Kernfunktionen von GPT-5.2-Codex
Bildnachweis: Openai
1. Langfristige Kodierung und projektbezogene Arbeit
GPT-5.2-Codex ist dafür ausgelegt, über ganze Codebasen hinweg zu arbeiten und nicht nur Snippets zu generieren. Es behält den Kontext über längere Sitzungen hinweg bei, wodurch es Folgendes ermöglicht:
- Führen Sie umfangreiche Refactorings durch.
- Führen Sie Migrationen durch.
- Entwickeln Sie Funktionen, die sich über mehrere Module erstrecken.
- Iterieren Sie komplexe Pläne, ohne dabei den Kontext während der Aufgabe zu verlieren.
Herkömmliche KI-Codierungsassistenten haben oft Schwierigkeiten, wenn Aufgaben viele Dateien umfassen oder über einfache Eingabeaufforderungen hinausgehen. GPT-5.2-Codex schließt diese Lücke mit robuster Kontextverfolgung und Workflow-Kontinuität.
2. Umfassende Codierungs-Benchmarks
Modernste Leistung bei Software-Engineering-Benchmarks untermauert die praktischen Fähigkeiten von GPT-5.2-Codex:
- Es erzielt hohe Punktzahlen bei SWE-Bench Pro, das realistische technische Aufgaben misst.
- Es schneidet bei Terminal-Bench 2.0 sehr gut ab, was auf seine Leistungsfähigkeit in realen Terminalumgebungen hinweist.
Diese Ergebnisse spiegeln nicht nur die Codegenerierung wider, sondern auch die Leistung auf Agentenebene – indem sie Maßnahmen ergreifen, wie es ein Entwickler tun würde.
3. Integrierte Tool-Ausführung und Kontextbewusstsein
GPT-5.2-Codex geht über die statische Codegenerierung hinaus:
- Es kann Screenshots und UI-Mocks in Code interpretieren.
- Es unterstützt eine verbesserte Tool-Nutzung und lässt sich zuverlässiger in native Umgebungen wie Windows integrieren.
- Es bewältigt langfristige Entwicklungszyklen mit Kontextpersistenz und Komprimierung, wodurch relevante Code-Historien erhalten bleiben.
Dadurch eignet es sich für Entwickler-Workflows, bei denen es unerlässlich ist, einen vollständigen Überblick über das Projekt zu behalten.
4. Verbesserte Cybersicherheitsfunktionen
GPT-5.2-Codex verfügt im Vergleich zu früheren Versionen über eine verbesserte Cybersicherheitslogik. Es kann dabei helfen, Schwachstellen zu identifizieren, Capture-the-Flag-Übungen durchzuführen und ethische Sicherheitsforschung zu unterstützen.
Diese doppelte Verwendbarkeit – sowohl zur Unterstützung der Softwareentwicklung als auch zur Verteidigungsarbeit – macht es zu einem einzigartigen Codierungsassistenten.
Wer sollte GPT-5.2-Codex verwenden?
GPT-5.2-Codex ist besonders wertvoll für:
- Professionelle Softwareentwickler, die komplexe Anwendungen erstellen
- Entwicklungsteams, die konsistente Multi-Modul-Ausgaben benötigen
- Cybersicherheitsanalysten, die Schwachstellen im Code untersuchen
- Toolchain-Ingenieure, die Aspekte von CI/CD-Pipelines automatisieren
Sein Design ermöglicht Autonomie auf Agentenebene, ohne dass Entwickler jeden Schritt im Detail kontrollieren müssen, während die menschliche Aufsicht dennoch gewährleistet bleibt.
GPT-5.2-Codex vs. Claude Code: Vergleich nebeneinander

Bei der Auswahl einer KI für die Programmierung sind Ende 2025 zwei der führenden Optionen GPT-5.2-Codex von OpenAI und Claude Code von Anthropic. Beide sind agentenbasierte Programmierassistenten, unterscheiden sich jedoch in ihren Stärken, Arbeitsabläufen und idealen Anwendungsfällen.
| Aspekt | GPT-5.2-Codex | Claude Code |
| Kernfokus | End-to-End-Engineering, projektbezogene Arbeitsabläufe | Lokale Workflows mit Entwicklerbeteiligung |
| Kontextbehandlung | Starke Langfristigkeit | Hohe lokale Kontextwahrnehmung |
| Benchmark-Leistung | Modernste agentenbasierte Codierung | Bei vielfältigen Aufgaben stark, bei einigen Benchmarks jedoch leicht im Rückstand |
| Codierungsstil | Detaillierter Code auf Unternehmensniveau | Lesbar, prägnant, prototyping-freundlich |
| Workflow-Integration | Cloud-Sandboxes + lokale Tools | Primär Terminal/IDE |
| Beste Anwendungsfälle | Umfangreiche Refactorings, Migrationen, komplexe Build-Pipelines | Schrittweise Refaktorisierung, Verständnis der Architektur, explorative Entwicklung |
Interpretation des Vergleichs
- GPT-5.2-Codex eignet sich hervorragend für größere technische Arbeitsabläufe, bei denen Kontinuität, Planung und mehrstufige Ausführung wichtig sind. Dank seiner Kontextverdichtung und integrierten Benchmarks ist es die erste Wahl für das Backend-Systemdesign und die Unternehmensentwicklung.
- Claude Code ist besonders leistungsstark, wenn Entwickler einen lokalen, interaktiven Codierungs-Workflow wünschen, der im Terminal und in der IDE ausgeführt wird und detaillierte Einblicke in die Architektur sowie schrittweise Anleitungen bietet.
In der Praxis verwenden viele Teams beide Tools: Codex für allgemeine, autonome Aufgaben und Claude Code, wenn eine tiefgehende, interaktive Untersuchung oder lokale Verfeinerung erforderlich ist.
Anwendungsfälle aus der Praxis
1. Groß angelegte Refactoring-Projekte
GPT-5.2-Codex kann:
- Verstehen Sie ganze Codebasen.
- Schlagen Sie Patches vor.
- Führen Sie Änderungen iterativ durch.
- Führen Sie Tests durch und aktualisieren Sie Workflows.
This makes it suitable for modernization efforts like migrating frameworks or reorganizing architecture.Dadurch eignet es sich für Modernisierungsmaßnahmen wie die Migration von Frameworks oder die Umgestaltung der Architektur.
2. Cybersicherheitsaudits und Schwachstellenanalyse
Die verbesserten Cybersicherheitsfunktionen des Modells helfen Teams dabei, Schwachstellenscans durchzuführen, Exploit-Verhalten zu analysieren und defensive Forschungsabläufe mit höherer Genauigkeit als bei Allzweckmodellen zu unterstützen.
3. IDE-Integration und Entwicklerbeschleunigung
Durch Codex CLI- und IDE-Erweiterungen können Entwickler:
- Code direkt in Editoren wie Visual Studio Code generieren
- Routineaufgaben wie Test-Scaffolding automatisieren
- Terminalbefehle für Echtzeit-Unterstützung verwenden
Diese enge Integration reduziert Kontextwechsel und steigert die Produktivität.
Conclusion
GPT-5.2-Codex stellt einen entscheidenden Schritt in der KI-gesteuerten Softwareentwicklung dar und kombiniert die neuesten Fortschritte von OpenAI mit einem Schwerpunkt auf agentenbasierten Codierungs-Workflows auf Projektebene. Seine Stärken in Bezug auf Kontextpersistenz, Benchmark-Leistung und Cybersicherheit machen es zu einem leistungsstarken Werkzeug für Unternehmen und professionelle Entwickler.
Im Vergleich dazu bleibt Claude Code eine wertvolle Option für interaktive, lokale Entwicklungserfahrungen und die Erforschung von Architekturen. Die Wahl zwischen den beiden Modellen sollte sich nach Ihren Workflow-Anforderungen richten – je nachdem, ob Ihre Priorität auf autonomer, langfristiger Entwicklung oder enger Terminal-/IDE-Interaktion liegt.
Zusammen spiegeln diese Tools die Entwicklung von KI-Codierungsassistenten im Jahr 2025 wider, in dem KI zu einem aktiven Partner in der Entwicklung wird und nicht mehr nur eine passive Engine für Code-Vorschläge ist. Mit zunehmender Verbreitung werden beide Modelle weiterhin Einfluss darauf haben, wie Entwickler Software erstellen, sichern und skalieren.
Häufig gestellte Fragen zu GPT-5.2-Codex
Wofür wurde GPT-5.2-Codex entwickelt?
Es handelt sich um ein spezialisiertes agentenbasiertes Codierungsmodell, das für komplexe Softwareentwicklungsaufgaben, umfangreiche Refactorings und Cybersicherheits-Workflows optimiert ist und die Fähigkeiten von GPT-5.2 für die Codierung in der Praxis erweitert.
Wie schneidet GPT-5.2-Codex im Vergleich zu Claude Code ab?
GPT-5.2-Codex zeichnet sich durch die Verarbeitung großer Codebasen und mehrstufiger Entwicklungsaufgaben mit hoher Benchmark-Leistung aus, während Claude Code häufig bei lokalen, interaktiven Terminal-Workflows und der Generierung lesbarer Codes gute Ergebnisse erzielt.
Wo ist GPT-5.2-Codex verfügbar?
Es wurde für zahlende ChatGPT-Nutzer in Codex-Oberflächen veröffentlicht, wobei ein breiterer API-Zugang unter kontrollierter Einführung geplant ist.
Kann GPT-5.2-Codex Entwickler ersetzen?
Es soll die Arbeitsabläufe im Engineering ergänzen, nicht menschliche Entwickler ersetzen; die menschliche Aufsicht bleibt für Architekturentscheidungen, Überprüfungen und die Produktionsreife weiterhin von entscheidender Bedeutung.
Welche Benchmarks zeigen seine Leistung?
Es zeigt starke Ergebnisse bei SWE-Bench Pro und Terminal-Bench 2.0, was auf seine Kompetenz bei realistischen Codierungsaufgaben hinweist.