MiMo-V2-Flash ist Xiaomis neuester Einstieg in die Welt der großen Sprachmodelle (LLMs) und bietet eine einzigartige Kombination aus hoher Inferenzgeschwindigkeit, effizienter Architektur und starker Benchmark-Leistung. Dieses Modell wurde im Dezember 2025 veröffentlicht und stellt einen wichtigen Meilenstein dar, insbesondere im Bereich der Open-Source-KI. Es umfasst auch Aufgaben wie Schlussfolgerungen, agentenbasierte Arbeitsabläufe und Codierung und hat aufgrund seiner innovativen Wettbewerbsfähigkeiten und seines Designs im Vergleich zu proprietären Branchenführern Aufmerksamkeit erregt.
In diesem Artikel erhalten Sie einen beeindruckenden Überblick über MiMo-V2-Flash. Dabei werden insbesondere seine Leistungsmerkmale, Architektur, praktische Anwendung, Kosteneffizienz und Auswirkungen auf Unternehmen und Entwicklung behandelt. Darüber hinaus gibt es einen detaillierten FAQ-Bereich, der einige der häufigsten Fragen zu MiMo-V2-Flash beantwortet.
Was ist MiMo-V2-Flash?
MiMo-V2-Flash ist ein von Xiaomi entwickeltes Open-Source-Sprachmodell vom Typ Mixture-of-Experts (MoE). Mit einer Gesamtparameteranzahl von 309 Milliarden, aber nur 15 Milliarden aktiven Parametern während der Inferenz, bietet es eine ungewöhnlich hohe Leistung bei gleichzeitig geringen Inferenzkosten und geringer Latenz. Das Modell ist für komplexe Schlussfolgerungen, Software-Engineering-Aufgaben und agentenbasierte Anwendungsfälle ausgelegt und eignet sich daher sowohl für Forschungs- als auch für Produktionsworkflows.
Xiaomi hat dieses Modell unter der MIT-Open-Source-Lizenz veröffentlicht, einschließlich Modellgewichten und Inferenzcode, was eine breite Nutzung und Integration über Plattformen hinweg ohne kommerzielle Einschränkungen ermöglicht.
Architektur und technische Innovationen
Mixture-of-Experts (MoE)-Design
MiMo-V2-Flash verwendet eine Mixture-of-Experts-Architektur, was bedeutet, dass der vollständige Parametersatz zwar groß ist (309 B), aber nur ein kleiner Teil (15 B) pro Token während der Inferenz aktiviert wird. Diese spärliche Aktivierung verbessert die Recheneffizienz erheblich, ohne die Leistungsfähigkeit zu beeinträchtigen.
Jede Anfrage wird selektiv über Experten-Subnetze weitergeleitet, sodass das Modell seine Wissensbasis skalieren und gleichzeitig den Rechenaufwand reduzieren kann. Dieses Design schafft ein Gleichgewicht zwischen Kapazität und Effizienz, das dichte Modelle in ähnlichen Größenordnungen nicht erreichen können.
Hybrid-Aufmerksamkeitsmechanismus
Ein wesentlicher Bestandteil der Modellarchitektur ist der Hybrid-Aufmerksamkeitsmechanismus. Anstatt für alle Schichten eine vollständige globale Aufmerksamkeit zu verwenden (die quadratisch mit der Sequenzlänge skaliert), verschachtelt das Modell:
- Sliding Window Attention (SWA) für die meisten Schichten
- Global Attention (GA) in ausgewählten Intervallen
Dieser Ansatz reduziert den Speicher- und Rechenaufwand und gewährleistet gleichzeitig ein effektives Verständnis des langfristigen Kontexts.
Multi-Token-Vorhersage (MTP)
MiMo-V2-Flash umfasst die Multi-Token-Vorhersage (MTP), eine spekulative Dekodierungstechnik, bei der das Modell mehrere Token-Entwürfe parallel vorschlagen und diese effizient validieren kann. Dies sorgt für eine erhebliche Beschleunigung der Inferenz, da die Ausgabe schneller generiert wird als bei herkömmlichen Single-Token-Dekodierungsansätzen.
Ultra-langes Kontextfenster
Eine der herausragenden Eigenschaften von MiMo-V2-Flash ist die Unterstützung eines 256 K (256.000) Token-Kontextfensters. Dies übertrifft die typischen 8K- oder 32K-Grenzen vieler LLMs bei weitem und ermöglicht es dem Modell, ganze Codebasen, umfangreiche Trainingsdokumente oder längere Multi-Turn-Konversationen zu verarbeiten, ohne den Kontext vorzeitig zu kürzen.
Leistungsbenchmarks und Fähigkeiten
Bildnachweis: xiaomi
Inferenzgeschwindigkeit
MiMo-V2-Flash kann bis zu 150 Token pro Sekunde verarbeiten und ist damit eines der schnellsten verfügbaren Open-Source-Modelle. Dieser Geschwindigkeitsvorteil ist besonders relevant für Echtzeitanwendungen, Codierungsassistenten und agentenbasierte Workflows, bei denen eine geringe Latenz entscheidend ist.
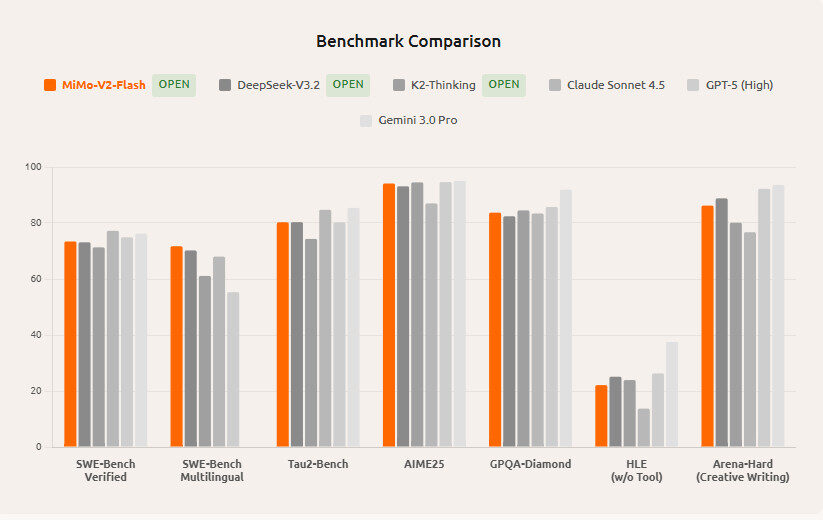
SWE-Bench Verified Leader
Im SWE-Bench Verified Benchmark, der Modelle hinsichtlich Software-Engineering- und Codierungsaufgaben bewertet, erreichte MiMo-V2-Flash eine Punktzahl von 73,4 % und rangiert damit an oder nahe der Spitze der Open-Source-Modelle. Diese Leistung in Verbindung mit seiner Effizienz macht es zu einer guten Wahl für Codierungs- und Schlussfolgerungsaufgaben.
Wettbewerbsfähigkeit mit proprietären Modellen
Obwohl MiMo-V2-Flash in erster Linie Open-Source ist, wurde es mit proprietären Systemen wie Claude Sonnet 4.5 und anderen hochmodernen Modellen verglichen. Unabhängige Berichte deuten darauf hin, dass seine Leistung bei bestimmten Aufgaben mit größeren oder geschlossenen Modellen vergleichbar oder sogar überlegen ist, insbesondere wenn man die Kosten und die Inferenzgeschwindigkeit berücksichtigt.
Breite Eignung für Aufgaben
Die Architektur und das Training von MiMo-V2-Flash machen es in folgenden Bereichen effektiv:
- Codegenerierung und Debugging
- Mathematisches Denken
- Langfristiges Denken und Analyse
- Mehrstufige Agentenaufgaben
Diese Vielseitigkeit erweitert seine Attraktivität über Einzweckmodelle hinaus.
Kosteneffizienz und Zugänglichkeit
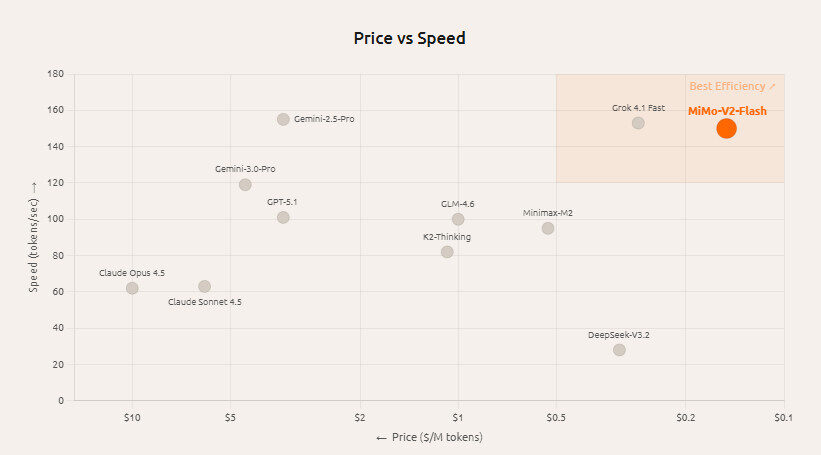
MiMo-V2-Flash stört die Wirtschaftlichkeit großer Sprachmodelle erheblich:
- Verbrauchskosten: Etwa 0,1 US-Dollar pro Million Eingabetoken und 0,3 US-Dollar pro Million Ausgabetoken bei Zugriff über unterstützte APIs.
- Open-Source-Lizenz: Die MIT-Lizenz ermöglicht es Benutzern, das Modell ohne Lizenzgebühren einzusetzen, zu modifizieren oder zu kommerzialisieren.
Diese Kombination aus niedrigen Kosten und offenen Lizenzen beseitigt viele Hindernisse, mit denen kleinere Entwickler oder Organisationen, die sich die hohen Gebühren für proprietäre Modelle nicht leisten können, normalerweise konfrontiert sind.
Anwendungen in der Praxis
Entwicklertools und Programmierassistenten
Aufgrund seiner starken Codierungs-Benchmarks und schnellen Inferenz eignet sich MiMo-V2-Flash gut für IDE-Integrationen, automatisierte Codegenerierung und Debugging-Assistenten. Entwickler können es für folgende Zwecke nutzen:
- Boilerplate-Code generieren
- Bestehende Codebasen umgestalten und optimieren
- Kontextbezogene Hilfe in Code-Editoren bereitstellen
Solche Tools können Entwicklungszyklen erheblich beschleunigen, insbesondere bei großen Codebasen.
KI-Agenten und interaktive Systeme
Agenten-Workflows erfordern Reaktionsfähigkeit und Zuverlässigkeit über mehrere Interaktionsrunden hinweg. Dank seiner Unterstützung für lange Kontexte und seiner Geschwindigkeit eignet sich MiMo-V2-Flash für interaktive KI-Agenten, die möglicherweise über viele Dialogrunden und Tool-Aufrufe hinweg den Kontext aufrechterhalten müssen.
Langform-Inhalte und Forschungsassistenten
Das erweiterte Kontextfenster macht MiMo-V2-Flash besonders geeignet für:
- Verarbeitung umfangreicher Dokumente
- Zusammenfassung umfangreicher Materialien
- Unterstützung von wissenschaftlichen Mitarbeitern, die den Kontext über viele Eingaben hinweg beibehalten müssen
Diese Funktion ist für Unternehmensabläufe, die mit rechtlichen, technischen oder akademischen Daten zu tun haben, unverzichtbar.
Wissenssynthese und Schlussfolgerungsaufgaben
Die hohe Leistung in den Benchmarks für logisches Denken lässt darauf schließen, dass das Modell Aufgaben unterstützen kann, die Folgendes erfordern:
- Logische Schlussfolgerung
- Analytische Problemlösung
- Beantwortung komplexer Fragen
Diese sind in Bereichen von entscheidender Bedeutung, in denen Entscheidungen auf einer integrierten Auswertung großer Datenmengen beruhen.
Entwicklerzugriff und Bereitstellungsoptionen
Open Source über Hugging Face
Die Modellgewichte von MiMo-V2-Flash können auf Plattformen wie Hugging Face heruntergeladen werden, sodass Forscher und Entwickler ohne Lizenzbeschränkungen Inferenzläufe durchführen oder Feinabstimmungen für bestimmte Anwendungen vornehmen können.
API-Zugriff und kostenlose Testversionen
Mehrere Plattformen bieten API-Zugriff auf MiMo-V2-Flash mit begrenzter kostenloser Nutzung. Diese APIs ermöglichen es Entwicklern, ohne Einrichtung oder Investitionen in die Infrastruktur mit dem Experimentieren zu beginnen, was die Prototypentwicklung und Skalierung von Anwendungen erleichtert.
Integration mit KI-Frameworks
Die Day-Zero-Unterstützung für Frameworks wie SGLang und andere optimierte Serving-Umgebungen beschleunigt die Bereitstellung, insbesondere hinsichtlich der Inferenzgeschwindigkeit und der Nutzung fortschrittlicher Dekodierungstechniken wie MTP.
Vergleich mit anderen Modellen
MiMo-V2-Flash ist zwar nicht das größte Modell hinsichtlich der Parameteranzahl, aber seine architektonischen Innovationen bieten im Vergleich zu vielen Modellen mit deutlich mehr Parametern eine wettbewerbsfähige Leistung und überlegene Effizienz.
| Funktion | MiMo-V2-Flash | Typisches dichtes LLM | Großes Closed-Source-Modell |
| Gesamtparameter | 309B | 500B+ | 800B+ |
| Aktive Parameter | 15B | 500B+ | 800B+ |
| Inferenzgeschwindigkeit | 150 tok/s | ~30–60 tok/s | ~40–80 tok/s |
| Kosten pro Token | ~$0.1–$0.3 | Höher | Deutlich höher |
| Lizenz | MIT Open Source | Variiert | Closed |
| Kontextfenster | 256K tokens | 8K–128K | ~128K |
Diese Tabelle verdeutlicht, wie MiMo-V2-Flash ein Gleichgewicht zwischen Umfang, Geschwindigkeit und Kosten herstellt, wodurch es für Anwendungen attraktiv ist, die Echtzeit-Durchsatz und Langzeitkontextverarbeitung zu geringeren Kosten erfordern.
Herausforderungen und Überlegungen
Komplexität der Implementierung
Das Modell ist zwar Open Source und frei zugänglich, doch um Spitzenleistungen wie 150 Token pro Sekunde zu erzielen, ist möglicherweise eine optimierte Infrastruktur erforderlich (z. B. mehrere GPUs mit hoher Speicherbandbreite). Entwickler müssen die Hardware-Bereitstellung entsprechend planen.
Architekturspezifität
Da pro Token nur 15 B Parameter aktiviert werden, ist das Verhalten des Modells nicht identisch mit dem von dichten Modellen, bei denen alle Parameter aktiv sind. Benutzer sollten diesen Unterschied beim Benchmarking oder Vergleichen von Ergebnissen berücksichtigen.
Qualitätsunterschiede zwischen den Aufgaben
Berichte der Open-Source-Community deuten darauf hin, dass MiMo-V2-Flash zwar in vielen Benchmarks hervorragende Ergebnisse erzielt, einige Aufgaben jedoch je nach Client, Prompt-Struktur oder Integrationsumgebung zu gemischten Ergebnissen führen können. Die Leistung kann variieren, insbesondere bei der Befolgung von Anweisungen außerhalb von Codierungs- oder Agentenaufgaben.
Schlussfolgerung
Das Konzept von MiMo-V2-Flash stellt eine bedeutende Veränderung im Bereich der Open-Source-Sprachmodelle dar. Mit einer Inferenzgeschwindigkeit von 150 kot/2, 309 Milliarden Parametern, einer effektiven MoE-Architektur und einem Kontextfenster von 256 K bietet es Entwicklern und Unternehmen eine außergewöhnliche Kombination aus Skalierbarkeit, Leistung und Kosteneffizienz.
Es verfügt über eine starke Benchmark-Leistung, insbesondere bei Codierungs- und Schlussfolgerungsaufgaben, sowie über offene Lizenzierungs- und Board-Zugriffsoptionen, was es zu einem vielseitigen Modell macht, das auch in der Lage ist, KI-Assistenten der nächsten Generation, analytische Workflows und Entwicklertools zu unterstützen. Da das digitale Ökosystem im Jahr 2026 und darüber hinaus weiter wachsen wird, wird MiMo-V2-Flash stets ein wettbewerbsfähiges und zugängliches Basismodell für praktische Anwendungen in verschiedenen Bereichen bleiben.
FAQs
Was ist MiMo-V2-Flash?
MiMo-V2-Flash ist ein Open-Source-Sprachmodell von Xiaomi, das auf dem Mixture-of-Experts-Ansatz basiert und über 309 Milliarden Parameter sowie 15 Milliarden aktive Parameter verfügt. Es wurde für Geschwindigkeit, Schlussfolgerungen und Codierungsaufgaben optimiert.
Wie schnell ist MiMo-V2-Flash?
Es erreicht eine Inferenzgeschwindigkeit von bis zu 150 Tokens pro Sekunde und ist damit deutlich schneller als viele offene und proprietäre Modelle.
Für welche Aufgaben eignet sich MiMo-V2-Flash am besten?
Es ist besonders stark in den Bereichen Codierung, agentenbasierte Workflows, Schlussfolgerungen und Anwendungen mit langem Kontext, wie z. B. Multi-Turn-Interaktionen und Dokumentenverarbeitung.
Ist MiMo-V2-Flash kostenlos nutzbar?
Ja – es wird unter einer MIT-Open-Source-Lizenz veröffentlicht, mit kostenlosen Modellgewichten und Inferenzcode, die für die Entwicklung zur Verfügung stehen.
Wie schneidet MiMo-V2-Flash im Vergleich zu anderen Modellen ab?
Es bietet ein ausgewogenes Verhältnis zwischen Parameterumfang, Geschwindigkeit und Kosten und übertrifft oft andere offene Modelle bei Codierungs-Benchmarks und konkurriert mit geschlossenen Modellen in Bezug auf Effizienz und Durchsatz.