MiMo-V2-Flash is Xiaomi’s latest entry into the world of large language models (LLMs), offering a unique combination of high inference speed, efficient architecture, and strong benchmark performance. This model was released in December 2025 and represents a major milestone, especially in open-source AI. It also includes tasks like reasoning, agentic workflow and coding, and has garnered attention for its innovative competitive capabilities and design as compared to proprietary Industry leaders.
In this article you will be getting an impressive overview of MiMo-V2-Flash. It will specifically include its performance characteristics, architecture, real-world application, cost efficiency and implications for enterprises and development. Besides this, to solve several other questions, there is a detailed FAQ section that will solve some of the common queries related to MiMo-V2-Flash.
What Is MiMo-V2-Flash?
MiMo-V2-Flash is an open-source Mixture-of-Experts (MoE) large language model developed by Xiaomi. With a total parameter count of 309 billion but only 15 billion active parameters during inference, it delivers unusually high performance while keeping inference cost and latency low. The model is designed to excel in complex reasoning, software engineering tasks, and agentic use cases, making it suitable for both research and production workflows.
Xiaomi released this model under the MIT open-source license, including model weights and inference code, enabling broad use and integration across platforms without commercial restrictions.
Architecture and Technical Innovations
Mixture-of-Experts (MoE) Design
MiMo-V2-Flash uses a Mixture-of-Experts architecture, meaning the full parameter set is large (309 B), but only a small fraction (15 B) is activated per token during inference. This sparse activation dramatically improves computational efficiency without sacrificing capability.
Each request selectively routes through expert subnetworks, allowing the model to scale its knowledge base while reducing computation. This design strikes a balance between capacity and efficiency that dense models cannot achieve at similar scales.
Hybrid Attention Mechanism
A key part of the model’s architecture is its hybrid attention mechanism. Instead of using full global attention for all layers (which scales quadratically with sequence length), the model interleaves:
- Sliding Window Attention (SWA) for most layers
- Global Attention (GA) at selected intervals
This approach reduces memory and computational demands while maintaining effective long-range context comprehension.
Multi-Token Prediction (MTP)
MiMo-V2-Flash incorporates Multi-Token Prediction (MTP), a speculative decoding technique where the model can propose multiple draft tokens in parallel and validate them efficiently. This provides significant inference speedups by generating output faster than traditional single-token decoding approaches.
Ultra-Long Context Window
One of the standout features of MiMo-V2-Flash is its support for a 256 K (256,000) token context window. This vastly exceeds the typical 8K or 32K limits seen in many LLMs and enables the model to process entire codebases, lengthy training documents, or extended multi-turn conversations without trimming context prematurely.
Performance Benchmarks and Capabilities
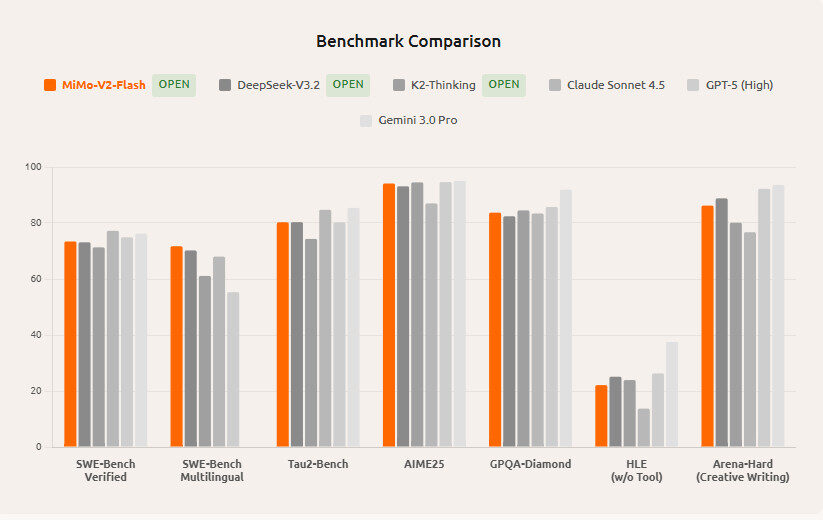
Image Credit: xiaomi
Inference Speed
MiMo-V2-Flash can process up to 150 tokens per second, making it one of the fastest open-source models available. This speed advantage is highly relevant for real-time applications, coding assistants, and agentic workflows where low latency is critical.
SWE-Bench Verified Leader
In the SWE-Bench Verified benchmark, which evaluates models on software engineering and coding tasks, MiMo-V2-Flash achieved a 73.4 % score, ranking it at or near the top among open-source models. This performance, combined with its efficiency, makes it a strong choice for coding and reasoning tasks.
Competitiveness with Proprietary Models
While primarily open-source, MiMo-V2-Flash has been benchmarked against proprietary systems such as Claude Sonnet 4.5 and other cutting-edge models. Independent reports suggest that its performance on certain tasks is comparable or even superior to larger or closed models, particularly when weighted against cost and inference speed.
Broad Task Suitability
MiMo-V2-Flash’s architecture and training make it effective across:
- Code generation and debugging
- Mathematical reasoning
- Long-form reasoning and analysis
- Multi-turn agent tasks
This versatility broadens its appeal beyond single-purpose models.
Cost Efficiency and Accessibility
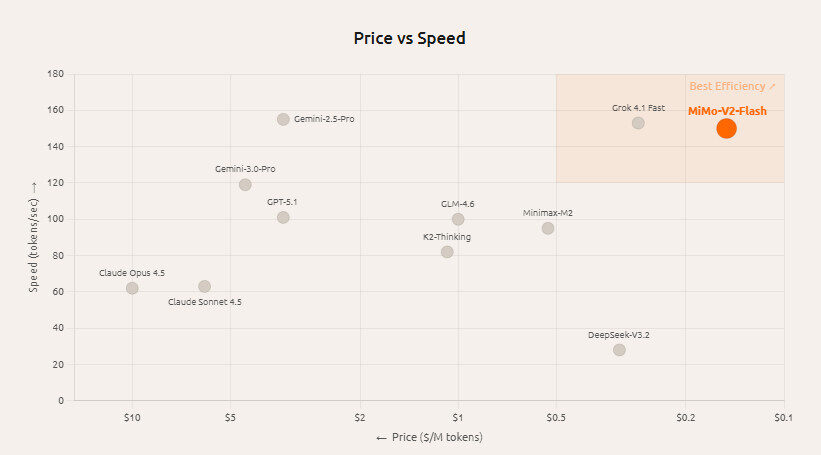
MiMo-V2-Flash significantly disrupts the economics of large language models:
- Consumption cost: Around $0.1 per million input tokens and $0.3 per million output tokens when accessed via supported APIs.
- Open-source license: MIT licence allows users to deploy, modify, or commercialize the model without licensing fees.
This combination of low cost and open licensing removes many barriers typically faced by smaller developers or organizations that cannot afford high fees for proprietary models.
Real-World Applications
Developer Tools and Coding Assistants
Given its strong coding benchmarks and fast inference, MiMo-V2-Flash is well suited for IDE integrations, automated code generation, and debugging assistants. Developers can use it to:
- Generate boilerplate code
- Refactor and optimize existing codebases
- Provide contextual help inside code editors
Such tools can significantly accelerate development cycles, especially in large codebases.
AI Agents and Interactive Systems
Agent workflows require responsiveness and reliability across multi-turn interactions. MiMo-V2-Flash’s long-context support and speed make it suitable for interactive AI agents, which may need to maintain context through many rounds of dialogue and tool calls.
Long-Form Content and Research Assistants
The extended context window makes MiMo-V2-Flash well suited for:
- Processing large documents
- Summarizing extensive material
- Supporting research assistants that must maintain context over many inputs
This capability is essential for enterprise workflows dealing with legal, technical, or academic data.
Knowledge Synthesis and Reasoning Tasks
High performance in reasoning benchmarks suggests the model can support tasks that require:
- Logical inference
- Analytical problem solving
- Complex question answering
These are critical in domains where decisions depend on integrated reasoning over large amounts of data.
Developer Access and Deployment Options
Open Source via Hugging Face
MiMo-V2-Flash model weights are available for download on platforms like Hugging Face, enabling researchers and developers to run inference or fine-tune for specific applications without licensing barriers.
API Access and Free Trials
Several platforms offer API access to MiMo-V2-Flash with limited free usage. These APIs allow developers to start experimenting without setup or infrastructure investment, making it easier to prototype and scale applications.
Integration with AI Frameworks
Day-zero support for frameworks like SGLang and other optimized serving environments accelerates deployment, particularly for inference speed and utilization of advanced decoding techniques like MTP.
Comparison with Other Models
While MiMo-V2-Flash is not the largest model by parameter count, its architectural innovations provide competitive performance and superior efficiency compared with many models that have significantly more parameters.
| Feature | MiMo-V2-Flash | Typical Dense LLM | Large Closed-Source Model |
| Total Parameters | 309B | 500B+ | 800B+ |
| Active Parameters | 15B | 500B+ | 800B+ |
| Inference Speed | 150 tok/s | ~30–60 tok/s | ~40–80 tok/s |
| Cost per Token | ~$0.1–$0.3 | Higher | Significantly Higher |
| Licence | MIT Open Source | Varies | Closed |
| Context Window | 256K tokens | 8K–128K | ~128K |
This table highlights how MiMo-V2-Flash balances scale, speed, and cost, making it appealing for applications that require real-time throughput and long-context handling at lower expense.
Challenges and Considerations
Implementation Complexity
While the model is open source and accessible, achieving peak performance, such as 150 tokens per second, may require optimized infrastructure (e.g., multiple GPUs with high memory bandwidth). Developers must plan hardware deployment accordingly.
Architecture Specificity
Because only 15 B parameters activate per token, the model’s behavior is not identical to dense models with all parameters engaged. Users should understand this difference when benchmarking or comparing outputs.
Quality Variation Across Tasks
Open-source community reports suggest that while MiMo-V2-Flash excels in many benchmarks, some tasks may yield mixed results depending on the client, prompt structure, or integration environment. Performance can vary, particularly in instruction following outside of coding or agent tasks.
Conclusion
The concept of MiMo-V2-Flash represents a significant shift in open-source large language models. By relying on 150 kot/2 inference speed, 309 billion parameters, effective MoE architecture and a 256 K context window, it provides developers and businesses an exceptional mix of scalability, performance and cost-effectiveness.
It has strong benchmark performance, especially in coding and reasoning tasks, as well as open licensing and board access options, making it a versatile model that is also capable of powering next-generation AI assistants, analytical workflows and developer tools. As the digital ecosystem continues to grow in 2026 and beyond, MiMo-V2-Flash will always stand as a competitive and accessible foundation model for practical application across various domains.
FAQs
What is MiMo-V2-Flash?
MiMo-V2-Flash is an open-source Mixture-of-Experts large language model from Xiaomi with 309 billion parameters and 15 billion active parameters, optimized for speed, reasoning, and coding tasks.
How fast is MiMo-V2-Flash?
It achieves up to 150 tokens per second inference speed, considerably faster than many open and proprietary models.
What tasks is MiMo-V2-Flash best suited for?
It is particularly strong in coding, agentic workflows, reasoning, and long-context applications such as multi-turn interactions and document processing.
Is MiMo-V2-Flash free to use?
Yes — it is released under an MIT open-source license, with free model weights and inference code available for development.
How does MiMo-V2-Flash compare with other models?
It balances parameter scale, speed, and cost, often outperforming other open models on coding benchmarks and rivalling closed models in efficiency and throughput.