
The rapid evolution of artificial intelligence has reached another pivotal moment. Moonshot AI, a Beijing-based startup valued at USD 3.3 billion and backed by Alibaba Group and Tencent. They have released the Kimi K2 Thinking model, sparking industry-wide discussion about whether U.S. dominance in frontier AI is being fundamentally challenged. With performance metrics surpassing OpenAI’s GPT-5 and Anthropic’s Claude Sonnet 4.5 across several high-rigour benchmarks, and a shockingly low training cost, this model is prompting comparisons to the earlier “DeepSeek moment” that transformed assumptions about cost-efficient AI scaling in China.
This article offers an in-depth look at the Moonshot AI Kimi K2 Thinking model, covering its architecture, performance benchmarks, API cost structure, parameters, and the broader strategic implications for the global AI ecosystem.
What Is Moonshot AI’s Kimi K2 Thinking Model?
The Kimi K2 Thinking model is Moonshot’s flagship open-source large language model designed for advanced reasoning, multi-step problem solving, and agentic automation. Released under a Modified MIT License on November 6, it provides commercial and derivative rights with minimal restrictions, a move that further intensifies competition between open and closed AI ecosystems.
Key highlights
- Fully open-weight, including training components
- Designed for long-chain reasoning and agentic tasks
- Built using a Mixture-of-Experts (MoE) architecture
- Uses only 32 billion active parameters per inference out of 1 trillion total
- Trained with INT4 quantisation for faster generation speeds
- Capable of 200–300 sequential tool calls autonomously
This combination of openness, efficiency, and high-level reasoning is what first drew attention from global AI researchers.
Kimi K2 Thinking Model Architecture
The core of Kimi K2 Thinking lies in its advanced MoE setup, which separates the massive 1-trillion-parameter model into specialized expert modules.
1. Mixture-of-Experts structure
- Total parameters: 1 trillion
- Active parameters per inference: 32 billion
- Efficiency benefit: Only a fraction of experts activate for each task, dramatically lowering compute costs without compromising accuracy.
2. INT4 quantisation
Moonshot AI applied INT4 quantisation during training, which:
- Cuts memory requirements
- Enables roughly 2× faster generation speeds
- Maintains near state-of-the-art precision
This use of low-bit quantisation at scale is one of the clearest indicators of China’s growing sophistication in cost-efficient model scaling.
3. Agentic reasoning capacity
The model can:
- Execute up to 300 continuous tool operations
- Maintain coherent reasoning over hundreds of task steps
- Perform complex research, browsing, or problem decomposition workflow sequences with minimal human oversight
This places Kimi K2 Thinking among the world’s most capable open-source agentic LLMs.
Kimi K2 Thinking Benchmarks: How It Surpassed GPT-5
The most disruptive aspect of Moonshot’s release is its exceptional performance on high-difficulty benchmarks used to measure deep reasoning, research capabilities, and agentic competence.
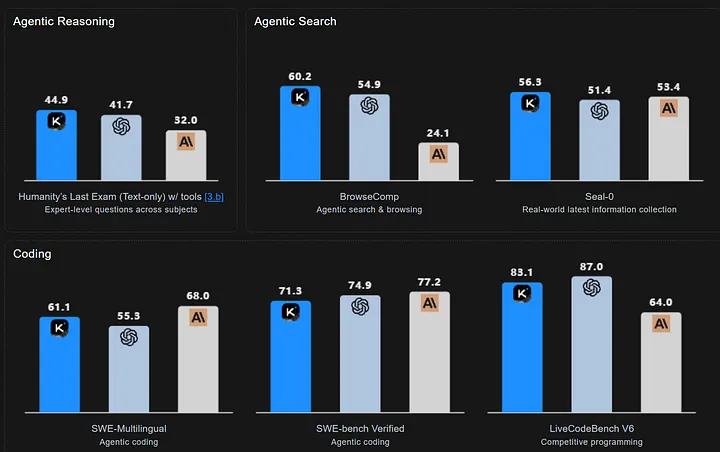
1. Humanity’s Last Exam
A widely recognized benchmark with 2,500 challenging questions across multiple domains.
- Kimi K2 Thinking: 44.9%
- OpenAI GPT-5: 41.7%
Outperforming GPT-5 in this benchmark has been called a watershed moment for open-source models.
2. BrowseComp Benchmark
Evaluates web-browsing proficiency, retrieval accuracy, and persistence of LLM agents.
- Kimi K2 Thinking: 60.2%
- Outplaced models from OpenAI and Anthropic
This score highlights the model’s strength in real-time research and autonomous browsing tasks.
3. Seal-0 Benchmark
Tests research-augmented models on realistic knowledge-intensive tasks.
- Kimi K2 Thinking: 56.3%
- Top score among all tested models
The model’s sustained reliability across multiple search-augmented test suites reinforces its strong agentic reasoning competencies.
4. Tau-2 Bench Telecom (Independent Evaluation)
Consultancy firm Artificial Analysis assessed Kimi K2 in a telecom-specific agentic stress test.
- Score: 93% accuracy; It is the highest ever performance the organization has ever measured.
This independent validation significantly bolstered global community confidence in Moonshot’s claims.
Kimi K2 Thinking Parameters and Technical Characteristics
| Feature | Specification |
| Total Parameters | ~1 trillion |
| Active Parameters per Inference | 32B |
| Architecture Type | Mixture-of-Experts |
| Quantisation | INT4 |
| Training Cost (reported) | ~$4.6 million (unconfirmed) |
| License | Modified MIT (with attribution requirements above certain scale) |
| Agentic Capacity | 200–300 autonomous tool calls |
| Performance Domain Strengths | Reasoning, browsing, coding, agent workflows |
Kimi K2 Thinking API: Cost Efficiency and Market Disruption
One of the most widely discussed aspects of Moonshot’s release is the incredible cost efficiency of its API.
API Pricing Insights
According to calculations by the South China Morning Post, the Kimi K2 Thinking API is:
- 6–10× cheaper than comparable OpenAI and Anthropic endpoints
- Positioned to drive massive adoption among startups, enterprise developers, and researchers
This is where the model most directly influences global competition; by reducing the barrier to high-performance AI deployment.
Why the K2 API is so cost-efficient
- MoE efficiency: drastically reduced active computation
- Quantisation: lower GPU memory footprint
- China’s optimized training pipeline: high throughput with reduced hardware spending
- Open-source release: lowers downstream scaling overhead
The model’s low API costs open doors for experimentation, new agentic products, and AI-native applications that would be prohibitively expensive using elite closed-source models.
Is This Another “DeepSeek Moment”?
Hugging Face co-founder Thomas Wolf asked whether this represents another “DeepSeek moment.” The comparison refers to DeepSeek’s earlier disruption of global AI expectations through cost-optimized scaling.
Similarities between DeepSeek and Kimi K2 Thinking:
- Both achieved frontier-level performance with drastically lower cost
- Both used MoE architectures and quantisation for efficient scaling
- Both demonstrated the rising competitiveness of Chinese labs that prioritize cost-performance optimization
Experts now believe such breakthroughs may occur every few months, accelerating the pace of innovation.
Limitations and Performance Gaps
Despite its impressive performance, researchers note that Kimi K2 Thinking is not yet fully on par with the absolute best closed-source systems.
Key limitations include:
- 4–6 month lag behind frontier U.S. models in raw general performance
- Limited transparency into Moonshot’s full training dataset sources
- INT4 quantisation may introduce slight performance trade-offs in nuanced tasks
- Real-time safety alignment and hallucination control are still evolving
Still, these gaps are narrowing steadily—faster than many U.S. leaders expected.
Market Implications: Cost-Effective Chinese AI Models Are Changing the Game
1. Shifting competitive focus toward cost efficiency
Chinese companies are strategically prioritizing cost reduction because competing head-to-head with top U.S. labs in pure model power remains challenging.
As Zhang Ruiwang, a Beijing-based IT architect, notes:
“Since performance still trails the top U.S. models, cost-effectiveness becomes the decisive advantage.”
2. The “cliff-like drop” in training costs
Analysts at iiMedia highlight a dramatic decline in Chinese training costs driven by:
- Efficient model architectures
- Novel training methods
- Better data curation
- Improved multi-node compute utilization
This challenges the long-held belief that frontier performance requires enormous capital.
3. License model creates new competitive pressure
Moonshot’s Modified MIT License allows full commercial use while requiring attribution only for:
- Apps serving >100M MAUs, or
- Businesses generating >$20M monthly revenue
This encourages mass adoption while preserving branding visibility at scale.
Industry Response
The global AI community has reacted strongly:
- Menlo Ventures’ Deedy Das called the release a “turning point” and a “seminal moment” for open-source AI.
- Nathan Lambert emphasized that labs like Moonshot and DeepSeek have “made the closed labs sweat”, citing increasing pricing pressure on U.S. companies.
- Analysts widely agree that the gap between elite closed models and open-weight releases has significantly narrowed.
These reactions illustrate that Kimi K2 Thinking is not a minor incremental improvement, it is a strategic inflection point.
Implications for Global AI Infrastructure
As model innovation accelerates, AI hardware strategy becomes increasingly important. The sector is entering a period of flux where:
- Partnerships like Tesla–Intel could reshape the global chip landscape
- Cost-efficient models may reduce dependency on scarce high-end GPUs
- Organizations must plan flexible, modular AI infrastructure to remain competitive
The choices made today regarding compute vendors, accelerators, and API partnerships will influence AI capability access for years to come.
Future Outlook: Can Moonshot Sustain This Advantage?
Whether Moonshot AI’s success represents a lasting competitive shift or a temporary convergence remains uncertain. Several factors will shape the long-term picture:
1. Sustained R&D investment
Moonshot must maintain significant funding to match the research velocity of OpenAI, Anthropic, and Google DeepMind.
2. Scaling safety and alignment
U.S. companies still hold a noticeable lead in aligned reasoning, factual grounding, and hallucination suppression.
3. Access to advanced compute
Chip supply constraints could impact China’s ability to scale future trillion-parameter models.
4. Global regulatory pressures
Open-source frontier models raise concerns about export controls, safety protocols, and replicability risks.
5. Enterprise adoption
The next six months will determine whether Kimi K2 Thinking becomes widely adopted by global enterprises or remains primarily within Asia.
Conclusion
Moonshot AI’s Kimi K2 Thinking model represents a remarkable milestone in global AI development. By outperforming GPT-5 and Claude Sonnet 4.5 on several rigorous benchmarks, achieving state-of-the-art reasoning ability, and delivering API access at a fraction of the cost, it challenges the long-held assumption that only the biggest U.S. labs can produce frontier-grade models.
While performance gaps remain—and the sustainability of this advantage is still uncertain—the release signals a new era of competition driven not only by raw capability but by cost-effective, open-source innovation. This marks the beginning of a long-term shift in global AI leadership that will depend on how quickly the world adapts to this new paradigm.
In the meantime, Kimi K2 Thinking stands as one of the most impressive examples of how intelligent architectural design, efficient training, and open-source principles can dramatically accelerate the democratization of advanced AI.