China-based Alibaba has released its strongest AI model, Qwen2.5-Max, poised to become one of the strongest generative AI models appearing in a rapidly rapid-developing environment where power is concentrated in a few giants: OpenAI and GPT-4o, Anthropic and Claude 3.5 Sonnet, and DeepSeek V3. A company capable of programming gigantic language models (LLMs) with relative ease, Alibaba is communicating that it is no longer riding on the outskirts of the global AI rush but is a key participant.
This article explores the nature of what Qwen2.5-Max presents, its architecture, benchmarks, performance compared to the competition, and its implications for developers and businesses alike.
What Is Qwen2.5-Max?
The latest flagship model in Alibaba’s Qwen series is Qwen2.5-Max, developed by the DAMO Academy in Artificial Intelligence. As a generalist AI model, Qwen2.5-Max is designed to perform various tasks, including text generation, summarization, coding, question answering, and more.
Unlike previous iterations of Qwen, which offered open-source versions, Qwen2.5-Max is proprietary, similar to OpenAI’s GPT-4o and Anthropic’s Claude 3.5 models. It’s trained on an enormous dataset comprising 20 trillion tokens, providing a wide-ranging knowledge base across multiple domains and languages.
However, it is not a reasoning model, meaning it doesn’t expose its internal logical processes like DeepSeek R1 or OpenAI’s o1. Instead, Qwen2.5-Max is optimized for performance, efficiency, and multi-tasking fluency—qualities critical for commercial applications.
Mixture-of-Experts (MoE) Architecture: A Smarter Way to Scale
Qwen2.5-Max utilizes a Mixture-of-Experts (MoE) architecture—an innovative model design also seen in DeepSeek V3. Instead of using all its parameters for every query, MoE activates only the “experts” or parts of the model most relevant to a given task.
Think of it as consulting a panel of specialists: If you ask a question about physics, only the physics experts respond, saving both time and computing resources.
The architecture is an influential alternative to high-density models such as GPT-4o or Claude 3.5 Sonnet, which apply all parameters in any task. MoE increases the compute-efficiency of Qwen2.5-Max enabling it to be highly scalable and responsive in intense situations like in the cloud-based apps or AI-as-a-service environments.
Training & Fine-Tuning: Combining Scale with Precision
The foundation of any robust AI model lies in the quality and scale of its training data—and Alibaba delivers impressively on both fronts:
- Training Size: 20 trillion tokens, equivalent to approximately 15 trillion words. To contextualize, that’s the same as ingesting 168 million copies of Orwell’s 1984.
- Supervised Fine-Tuning (SFT): Alibaba employed human annotators to teach the model to provide high-quality, informative answers across diverse contexts.
- Reinforcement Learning from Human Feedback (RLHF): Similar to OpenAI’s alignment training, this step ensures the model prioritizes user intent and produces contextually relevant, human-like responses.
This dual refinement process equips Qwen2.5-Max with not only breadth of knowledge but also alignment with human expectations—a key differentiator in LLM deployment.
Benchmark Performance: Where Qwen2.5-Max Stands
Instruct Model Benchmarks
These tests reflect the model’s capabilities in real-world applications such as conversation, coding, and general problem-solving:

Source: QwenLM
| Benchmark | Qwen2.5-Max | Claude 3.5 Sonnet | GPT-4o | DeepSeek V3 |
| Arena-Hard (Preference) | 89.4 | 85.2 | N/A | 85.5 |
| MMLU-Pro (Reasoning) | 76.1 | 78.0 | 77.0 | 75.9 |
| GPQA-Diamond (Knowledge QA) | 60.1 | 65.0 | N/A | 59.1 |
| LiveCodeBench (Coding) | 38.7 | 38.9 | N/A | 37.6 |
| LiveBench (Overall) | 62.2 | 60.3 | N/A | 60.5 |
Key Insight: Qwen2.5-Max consistently outperforms DeepSeek V3 in every benchmark, even surpassing Claude 3.5 in areas such as overall preference (Arena-Hard) and general performance (LiveBench).
Base Model Benchmarks: suitable the Open-Weight Pack
While GPT-4o and Claude 3.5 remain closed-source, comparisons among open-weight models reveal Qwen2.5-Max’s supremacy:
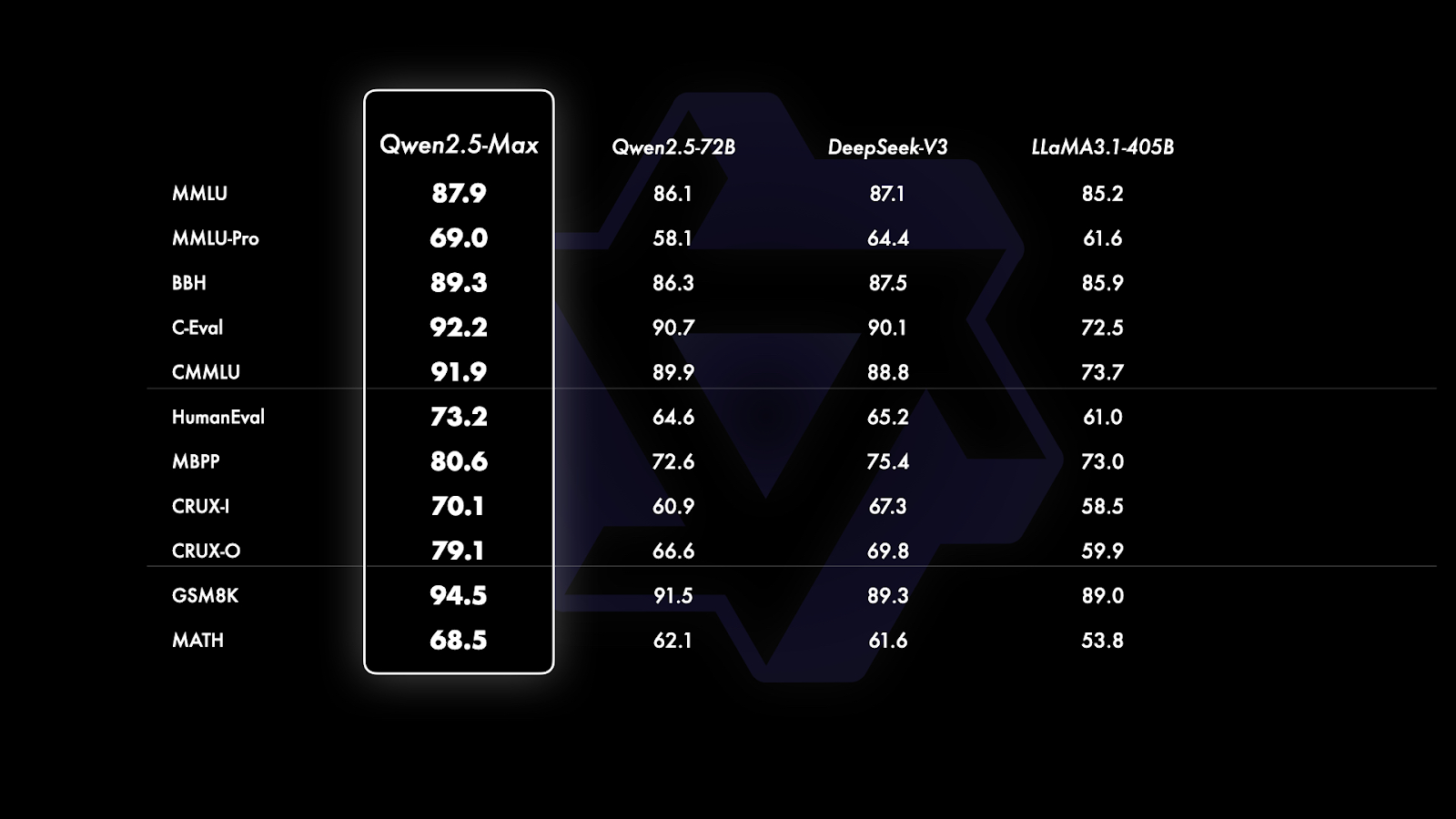
Source: QwenLM
General Knowledge & Language Understanding
- MMLU: 87.9 (vs. DeepSeek V3’s 85.5)
- C-Eval (Chinese academic tasks): 92.2 (suitable-in-class)
- BBH, CMMU, AGIEval: Outperformed all rivals
Programming & Logical Reasoning
- HumanEval: 73.2
- MBPP (Python problems): 80.6
- CRUX-O/I: Outshines DeepSeek V3 by ~5%
Mathematical Problem Solving
- GSM8K (Grade School Math): 94.5
- MATH (Advanced): 68.5 (slightly ahead of competitors)
Conclusion: In every core LLM domain—language, coding, math—Qwen2.5-Max demonstrates consistent superiority among publicly testable models.
Qwen 2.5 Max vs DeepSeek AI: Alibaba Claims Dominance Over DeepSeek V3 & ChatGPT
With the AI race intensifying, the release of Qwen2.5-Max aims to dethrone DeepSeek V3 as the suitable MoE model in the open-weight category.
Qwen2.5-Max Strengths:
- Outperforms DeepSeek V3 across nearly all standard benchmarks
- MoE architecture with a better efficiency-to-performance ratio
- Strong performance in both coding and mathematical tasks
- Chinese language benchmarks (C-Eval, CMMU) dominance
DeepSeek V3 Strengths:
- Transparent documentation and active open-source community
- Proven performance on reasoning and interpretability tasks
- Earlier entry and stronger developer ecosystem
Verdict: While DeepSeek V3 remains formidable, Qwen2.5-Max leapfrogs it in most areas—especially in generalist tasks, coding, and multilingual understanding. For developers, Alibaba’s model offers compelling incentives to switch or at least test its capabilities side-by-side with GPT-4o or Claude 3.5 Sonnet.
Real-World Use Cases
The relevance of Qwen2.5-Max extends beyond academic benchmarks. Here’s how it’s already proving useful:
1. Enterprise Chatbots
Enterprise clients of Alibaba are integrating Qwen2.5-Max in intelligent service agents to facilitate e-commerce systems, such as Taobao and Tmall to have a better intelligent agent to support customers and facilitate their transactions.
2. Cloud-AI Automation
Integrated into Alibaba Cloud’s Model Studio, Qwen2.5-Max supports business process automation, AI-driven analytics, and document summarization tools used by finance, logistics, and retail sectors.
3. Education and Tutoring
Qwen2.5-Max has been piloted in AI-based tutoring systems. It offers detailed problem-solving walkthroughs in mathematics, code evaluation, and exam preparation.
Accessing Qwen2.5-Max
1. Qwen Chat Interface
Aimed at casual users and researchers, the Qwen Chat web portal enables real-time conversation with Qwen2.5-Max. Visit the site, select the model from the dropdown, and start chatting—no installation required.
2. Alibaba Cloud Model Studio API
Qwen2.5-Max can be integrated via API access from Alibaba Cloud for developers and enterprises. The interface is designed to be compatible with OpenAI’s API standards, streamlining the transition for teams already using GPT-4 or Claude APIs.
Full documentation and token pricing are available on Alibaba Cloud’s official website.
Final Thoughts: A Global AI Power Play
Qwen2.5-Max marks Alibaba’s most serious play yet in the global AI arena. Its robust performance, scalable architecture, and real-world readiness place it squarely in competition with the most advanced models from the West.
While it lacks the transparency of an open-source model, its availability via API and user-friendly interface offset that concern for many developers; as Alibaba continues to refine its offerings and potentially releases a reasoning-focused Qwen 3, we may witness the rise of a true third force in global AI alongside OpenAI and Anthropic.
Bottom Line: Qwen2.5-Max isn’t just catching up—it’s setting the pace in many respects. This model is worth exploring for users, developers, and organizations invested in leveraging the latest AI.