Einführung: Ein neuartiges Vision-Language-Modell
Vision Language Models (VLMs) stehen an der Spitze der multimodalen KI – sie verstehen sowohl Bilder als auch Text. Ein neuer Typ von Vision Language Model, FastVLM, der von Apple-Forschern auf der CVPR 2025 vorgestellt wurde, erweitert die Grenzen der VLM-Leistung. FastVLM wurde für Echtzeit-VLM-Anwendungen und die Effizienz von VLM auf Geräten entwickelt und verbessert den Kompromiss zwischen Genauigkeit und Latenz von FastVLM erheblich, ohne die Fähigkeit zur Verarbeitung hochauflösender Bilder zu beeinträchtigen.
Bildquelle: Apple
Das Dilemma zwischen Genauigkeit und Latenz in visuellen Sprachmodellen
Bei herkömmlichen VLMs steigt die Genauigkeit mit der Bildauflösung – insbesondere bei Aufgaben wie der Dokumentenanalyse, der UI-Navigation und dem Verständnis fein strukturierter Szenen. Höhere Auflösungen verlängern jedoch die Time-to-First-Token (TTFT) – die Summe aus der Latenz des Vision-Encoders und der Vorfüllzeit des LLM –, was ein praktisches Hindernis darstellt, wenn Echtzeitleistung oder datenschutzkonforme VLM-Apps auf dem Gerät angestrebt werden.
FastVLM löst dieses Problem durch einen hybriden Bildencoder und eine Architektur namens FastViTHD, die für hochauflösende Eingaben optimiert ist. Dies ermöglicht eine neue Generation hybrider Bildencoder für VLMs, die sowohl Geschwindigkeit als auch Genauigkeit bieten.
FastViTHD-Architektur erklärt: Hybrides Design für optimale Leistung
FastViTHD – kurz für „Fast Vision Transformer High-Definition“ – ist das Rückgrat von FastVLM. Es kombiniert Convolutional- und Transformer-Blöcke in einem fünfstufigen Encoder-Design. Die ersten drei Stufen verwenden Convolutional-„RepMixer“-Blöcke, die letzten beiden nutzen Multi-Headed Self-Attention. Auf strategischer Ebene stellt eine weitere Stufe des Downsamplings sicher, dass die Tokens auch bei einer hohen Auflösung wesentlich weniger werden – nämlich viermal weniger als bei FastViT und sogar 16-mal weniger als bei ViT-L/14 – und gleichzeitig eine geringe Latenz beibehalten wird.
Darüber hinaus erhöht die Integration von Multi-Scale-Features (über Tiefenkonvolutionen anstelle von Average Pooling) die Genauigkeit bei VLM-Benchmarks wie TextVQA oder DocumentVQA – und das bei gleichzeitig geringen Codierungszeiten.
Visuelle Token-Qualität in FastVLM
FastViTHD generiert visuell hochwertigere Token, wodurch die Abhängigkeit von Token-Pruning-Methoden deutlich reduziert wird. Diese hochauflösenden Token vereinfachen die MLP-Projektionsschicht für visuelle Token auf den LLM-Einbettungsraum – komplexe Zusammenführungs- oder Komprimierungsstrategien sind nicht erforderlich.
FastVLM-Genauigkeit vs. Latenz-Kompromiss
FastVLM, basierend auf FastViTHD, bietet das geeigneten Verhältnis zwischen Genauigkeit und Latenz unter den Vision-Language-Modellen:
- 85× schnellere TTFT im Vergleich zu LLaVA-OneVision (0,5B LLM) bei einer Auflösung von 1152×1152, bei gleicher Genauigkeit.
- Bei denselben Benchmarks (SeedBench, MMMU) schneidet FastVLM vergleichbar ab, verwendet jedoch einen 3,4× kleineren Vision-Encoder.
- Selbst größere Varianten (mit Qwen2-7B LLM) übertreffen Cambrian-1-8B-Modelle mit einer 7,9× schnelleren TTFT.
Dies zeigt einen unübertroffenen Kompromiss zwischen Genauigkeit und Latenz bei VLMs, der eine schnelle Reaktion mit einem hochpräzisen Verständnis in Einklang bringt.
Vergleich zwischen FastVLM und Token Pruning, Dynamic Tiling (AnyRes) und traditionellen Architekturen
FastVLM vs. Token-Pruning-Methoden
Token-Pruning- oder Merging-Techniken (z. B. die heuristische Reduzierung visueller Token) führen oft zu einer erheblichen Komplexität der Architektur. FastVLM hingegen vermeidet dies von Natur aus durch das effiziente Encoder-Design von FastViTHD – und erzielt so eine starke Leistung mit einer eleganteren Architektur.
FastVLM vs. dynamisches Tiling (AnyRes)
Beim dynamischen Tiling werden hochauflösende Bilder in Kacheln aufgeteilt, einzeln verarbeitet und die Token zusammengeführt. Diese Methode ist zwar nützlich, erhöht jedoch aufgrund der wiederholten Codierung oft die Latenz. Die Autoren zeigen, dass FastVLM ohne Tiling bei der Abwägung zwischen Genauigkeit und Latenz selbst bei sehr hohen Auflösungen besser abschneidet als kachelbasierte Ansätze. Nur bei extremen Auflösungen bringt die Kombination von FastVLM mit AnyRes einen marginalen Gewinn.
FastVLM im Vergleich zu herkömmlichen VLMs
Im Vergleich zu beliebten VLMs:
- LLava-OneVision (0,5 Mrd.): FastVLM ist 85-mal schneller und 3,4-mal kleiner.
- SmolVLM (~0,5 Mrd.): FastVLM ist 5,2-mal schneller.
- Cambrian-1 (7 Mrd.): FastVLM ist 21-mal schneller und bietet bessere oder vergleichbare Leistungsmetriken.
FastVLM vs. FastViT vs. ConvNeXT: Vergleich der Architektur
FastViT ist eine frühere Hybridarchitektur, die Convolutional- und Transformer-Pfade mit hoher Geschwindigkeit und Genauigkeit kombiniert. Sie nutzt strukturelle Reparametrisierung und RepMixer-Schichten, um ein schnelles, genaues und effizientes Bildverständnis auf mobiler Hardware zu erreichen.
FastViTHD baut auf FastViT auf und fügt Architekturelemente für hochauflösende VLMs hinzu:
- Zusätzliche Downsampling-Stufe
- Multiskalige Funktionen
- Optimierte Token-Reduzierung und Latenz.
In der Praxis wurde FastViTHD zusammen mit FastViT und ConvNeXT getestet. Dabei zeigte es sich, dass FastViTHD in hochauflösenden Szenarien überlegen ist. Sein Vorsprung liegt darin, dass FastViTHD eine niedrigere Bildlatenz hat und gleichzeitig eine bessere Retrieval-Performance bietet.
Zeit bis zum ersten Token und Effizienz der geräteinternen VLM
FastVLM reduziert die Zeit bis zum ersten Token (TTFT) erheblich: die kritische Latenzmetrik in VLM-Pipelines, die den Encoder und die anfängliche LLM-Antwort umfasst. Mit FastViTHD wird die TTFT je nach Auflösung und Modellvariante um den Faktor 3 bis 85 reduziert, wodurch Echtzeit-VLM-Anwendungen auf Geräten möglich werden.
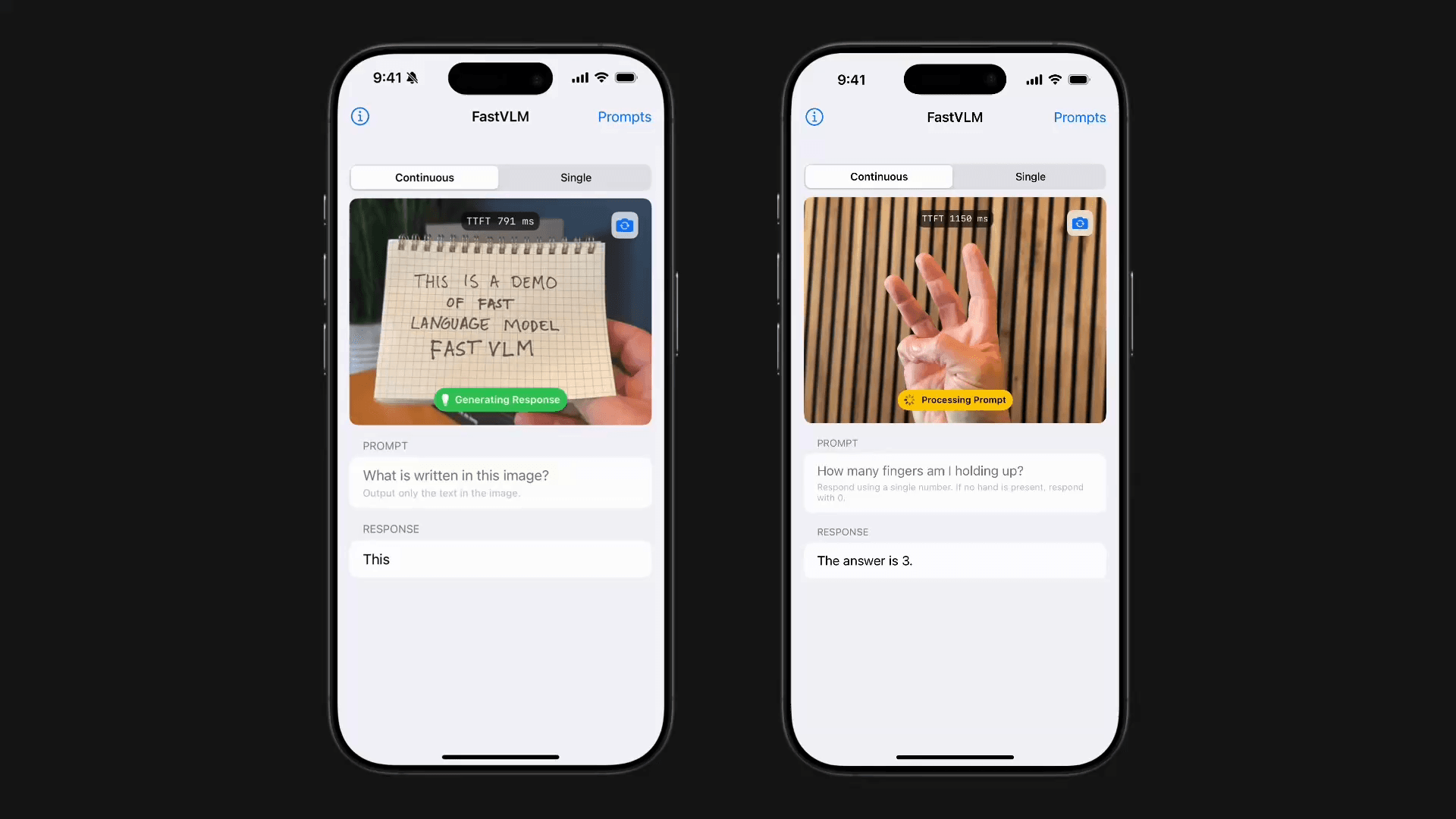
Vorführungen auf dem Gerät
Über MLX hat Apple eine Demoversion für iOS und macOS veröffentlicht, mit der gezeigt wird, dass FastVLM auf Apple Silicon mit geringer Latenz zu überführen ist. Das ist genau das, was Datenschutzzertifizierte VLM-Apps für Geräte wie Assistenten, UI-Navigatoren, und AR-Tools benötigen.
Echtzeit-VLM-Anwendungen und Anwendungsfälle
Aufgrund seiner geringen Latenz und hohen Genauigkeit ermöglicht FastVLM zahlreiche Echtzeit-VLM-Anwendungen:
- Barrierefreiheitsassistenten: Geräteinterne Schnellbeschreibung von Szenen und Texten für sehbehinderte Benutzer.
- UI-Navigation und Robotik: Schnelle visuelle Befehlsinterpretation ohne Cloud-Verzögerung.
- Echtzeit-Gaming: Hochauflösendes Szenenverständnis für AR/VR-Assistenten.
- Dokumentenanalyse: Genaue Verarbeitung von juristischen Dokumenten oder Verträgen mit hochauflösenden Details.
- Datenschutzrelevante Aufgaben: Geräteinterne Leistung, die sicherstellt, dass Benutzerdaten niemals das Gerät verlassen.
Skalierbarkeit: Abwägen zwischen LLM-Größe und Bildauflösung
Die FastVLM-Forschung untersucht den Kompromiss zwischen der Skalierung der LLM-Größe und der Bildauflösung. Unter Verwendung mehrerer LLM-Decoder (0,5 Mrd., 1,5 Mrd., 7 Mrd.) berechnen sie Pareto-optimale Kurven und ermitteln so die geeigneten Leistung für suitableimmte TTFT-Budgets.
Wichtigste Erkenntnis: Die Kombination einer moderaten Bildauflösung mit einem LLM angemessener Größe führt oft zu besseren Ergebnissen als eine einfache Erhöhung der Auflösung. FastVLM erreicht im Vergleich zu herkömmlichen Setups eine bis zu dreimal schnellere Laufzeit bei gleicher Genauigkeit.
Aufschlüsselung der technischen Komponenten
- FastVLM-Architektur: Vision-Encoder (FastViTHD) + MLP-Projektion + LLM-Decoder.
- FastViTHD-Backbone-Design: 5 Stufen mit Convolutional- und Transformer-Layern; Downsampling optimiert für Token- und Latenzreduzierung.
- Hybride Convolutional-Transformer-Vision-Encoder: FastViTHD stellt eine Anwendung dar, bei der Convolutional und Transformer-Modelle zusammen benutzt werden, um die Effizienz der Verarbeitung von Bildauflösungen zu steigern.
- MLP-Projektionsschicht: Ordnet visuelle Token vom Vision-Encoder nahtlos in den LLM-Einbettungsraum ein.
- Qualität der visuellen Token: Höher als bei FastViTHD, wodurch die Notwendigkeit des Token-Pruning oder der Token-Zusammenführung reduziert wird.
Vergleichende Zusammenfassung
| Funktion / Vergleich | FastVLM (mit FastViTHD) | Konkurrierende Architekturen |
|---|---|---|
| TTFT Beschleunigung | Bis zu 85× schneller | LLaVA-OneVision, Cambrian-1 deutlich langsamer |
| Vision-Encoder-Größe | 3.4× kleiner | LLaVA-OneVision, ViT-L/14 sind groß |
| Hybrid-Encoder | FastViTHD (Konvolution + Transformer) | ViT-L/14 (Transformer), ConvNeXT (nur Conv) |
| Token-Bereinigung | Kein Beschneiden erforderlich | Viele Methoden erfordern komplexe Token-Zusammenführungen. |
| Kachelbasierte Verarbeitung (AnyRes) | Nicht erforderlich; hilft nur bei extremen Auflösungen | Nützlich, aber insgesamt oft langsamer |
| Skalierbarkeit (LLM vs. Auflösung) | Pareto-optimale Balance möglich | Häufig suboptimale/ineffiziente Kombinationen |
| Durchführbarkeit auf dem Gerät | Demonstriert über die iOS/macOS MLX-App | Häufig auf Cloud oder hohe Latenz ausgerichtet |
Fazit: FastVLM ebnet den Weg für agile, präzise visuelle KI
FastVLM markiert einen Meilenstein in der Entwicklung von Vision Language Models. Durch die Lösung des Kompromisses zwischen Genauigkeit und Latenz, insbesondere beim Verstehen hochauflösender Bilder, ermöglicht es Echtzeit-, geräteinterne und datenschutzsichere VLM-Anwendungen für den täglichen Gebrauch.
Von Barrierefreiheitsassistenten und Robotersteuerung bis hin zu Dokumentenanalyse und Echtzeit-Gaming eröffnet FastVLM eine Vielzahl leistungsstarker Anwendungsfälle und schließt die Lücke zwischen Leistung und Effizienz ohne Kompromisse.
FAQs
Was ist FastVLM?
FastVLM ist ein neuartiges Bildverarbeitungsmodell, das die Verarbeitung von Bildern mit viel höherer Auflösung ermöglicht, dabei aber wesentlich schneller ist als bisherige Modelle, ohne dabei an Genauigkeit einzubüßen. Dadurch eignet es sich für Echtzeit- und On-Device-Anwendungen.
Wie verbessert FastViTHD die Leistung?
FastViTHD kombiniert Faltungs- und Transformer-Schichten mit intelligenter Token-Reduktion, um die Bildverarbeitung zu beschleunigen und gleichzeitig eine hohe Genauigkeit zu gewährleisten, selbst bei hohen Auflösungen.
Warum ist die Zeit bis zum ersten Token (TTFT) wichtig?
TTFT gibt an, wie schnell ein Modell nach dem Erkennen eines Bildes mit der Textgenerierung beginnen kann. FastVLM reduziert diese Latenzzeit erheblich und sorgt so für eine nahtlose und sofortige Reaktionsfähigkeit in realen Anwendungen.
Kann FastVLM auf Geräten wie Smartphones oder Laptops ausgeführt werden?
Ja, es läuft effizient auf Apple Silicon-Geräten und unterstützt schnelle, datenschutzfreundliche Anwendungen, ohne dass eine Cloud-Verarbeitung erforderlich ist.
Was sind häufige Anwendungsbereiche für FastVLM?
FastVLM eignet sich gut für Barrierefreiheits-Tools, UI-Navigation, Dokumentenanalyse, AR/VR-Spiele und alle Szenarien, in denen eine schnelle und genaue Bildverarbeitung auf dem Gerät erforderlich ist.