Artificial intelligence development has been unstoppable in the years 2024 and 2025; however, Kimi K2.5 remains a breakthrough everlasting in the field of open-source AI models. It combines powerful multimodal reasoning, agentic execution and practical driving ability that solves real-world problems and supports programming, document processing and large-scale research workflows.
Constructed with a trillion-parameter Mixture-of-Experts architecture that is endowed with strong vision, language and agent swarm capabilities, Kimi 2.5 redefines what is possible for increase through open source AI nowadays.
Video Credit: Kimi
A New Class of Open-Source Model
What Is Kimi K2.5?
Kimi K2.5 is a fully open-source multimodal large language model developed by Moonshot AI and released in early 2026. It evolved from prior versions (e.g., Kimi K2), undergoing extensive continued pretraining on approximately 15 trillion vision and text tokens to integrate visual understanding with language and agentic reasoning.
Unlike many primarily text-based models, K2.5 is native multimodal from the ground up. This means it processes text, images and video together in a single architecture. That capability enables it to translate visual design, screenshots and video content into executable outputs, such as code or structured documents.
Why the “2.5” Version Matters
The jump to “2.5” is more than incremental. Kimi’s developers focused on three core areas:
- Multimodal learning at scale, making it stronger than previous generations at tasks involving images and video.
- Agent swarm execution, enabling parallel reasoning and task breakdown.
- Real-world productivity, letting the model handle complex workflows end-to-end.
Together, these improvements enhance performance in large-context reasoning, agentic tasks, visual coding and document automation.
Core Technical Innovations
Native Multimodal Reasoning
Kimi K2.5’s architecture combines textual and visual training from the start. It uses a MoonViT encoder in its neural backbone to process images alongside text. This design gives the model a robust understanding of visual context, from screenshots to video frames, enabling tasks like
- Turning UI mockups or sketches into production-ready code.
- Debug code by reviewing visual screenshots.
- Extracting structured elements from video.
This design contrasts with systems where vision and text are trained separately and combined later. Native integration allows K2.5 to reason over visual and textual modalities without translation loss.
Massive Context Capacity
One of K2.5’s defining features is its large context window up to 256,000 tokens. This allows the model to reason over long codebases, documents, or datasets without fragmenting context, which is a common limitation in smaller models.
For comparison, many competitive models operate with context windows around 200K or less, meaning K2.5 can process broader scopes of information continuously.
Mixture-of-Experts Architecture
K2.5 uses a Mixture-of-Experts (MoE) design. This means that although the model has about 1 trillion total parameters, only a subset (around 32 billion) activates per token during inference. This enables:
- Efficient use of computational resources.
- Specialized reasoning via expert submodules.
- Better performance across diverse tasks.
MoE architectures are widely used in the most powerful LLMs because they balance scale with inference efficiency.
Agent Swarm Paradigm
Perhaps its most innovative feature is Agent Swarm, which lets K2.5 dynamically create and manage up to 100 independent sub-agents that work in parallel on a task. This design is trained with Parallel-Agent Reinforcement Learning (PARL) to break tasks into subtasks without human-defined workflows.
Instead of one agent processing a task sequentially, each sub-agent can operate on parts of the task in parallel, pooling results toward a final solution. Early internal evaluations show that agent swarm execution can reduce task runtime by up to 4.5× compared with sequential execution.
This allows K2.5 to scale beyond traditional single-agent capabilities in:
- Large-scale research synthesis.
- Multi-stage software engineering tasks.
- Competitive analysis and large-context discovery.
Real-World Capabilities and Use Cases
Visual Coding and UI Construction
A standout capability of K2.5 is visual coding. Users can feed an image or video of a design and receive fully functional front-end code that matches the visual layout and design intent. This goes beyond simple text-to-code translation by incorporating pixel-level reasoning and layout understanding.
In practical terms, this means:
- UI designers can hand over sketches or mockups to K2.5 and receive working HTML/CSS/JS prototypes.
- Developers can generate complex interactive workflows from video walkthroughs.
- Visual debugging becomes more efficient as errors identified in screenshots can be translated into actionable code fixes.
This reduces the gap between design and development, lowering friction in product workflows.
Parallel Research and Knowledge Work
Agent Swarm lets K2.5 excel at large-scale research tasks. For example:
- Market or competitive analysis across many sources simultaneously.
- Compilation and synthesis of long literature reviews.
- Extraction of insights from datasets or broad web content.
In benchmarks and internal tests, Agent Swarm improved performance significantly on wide-search problems, demonstrating why this paradigm matters for productivity-heavy tasks.
Document and Office Automation
K2.5 isn’t just for code. It can generate:
- Word documents with annotations.
- PDFs with embedded LaTeX equations.
- Spreadsheets with pivot tables and financial models.
- Complete slide decks for presentations.
These capabilities make it practical for business knowledge workers who need large-scale content creation, not just code.
Spreadsheet
Doc
Slide
Coding Assistance and Debugging
Benchmarks show K2.5 performs well on coding tasks compared with other open-source and closed models. For instance:
- SWE-Bench Verified scores around 76.8% in recent evaluations.
- HLE Full and other complex reasoning benchmarks show strong agentic and reasoning performance.
These scores demonstrate that K2.5 isn’t just theoretically powerful; it delivers competitive results on practical engineering problems.
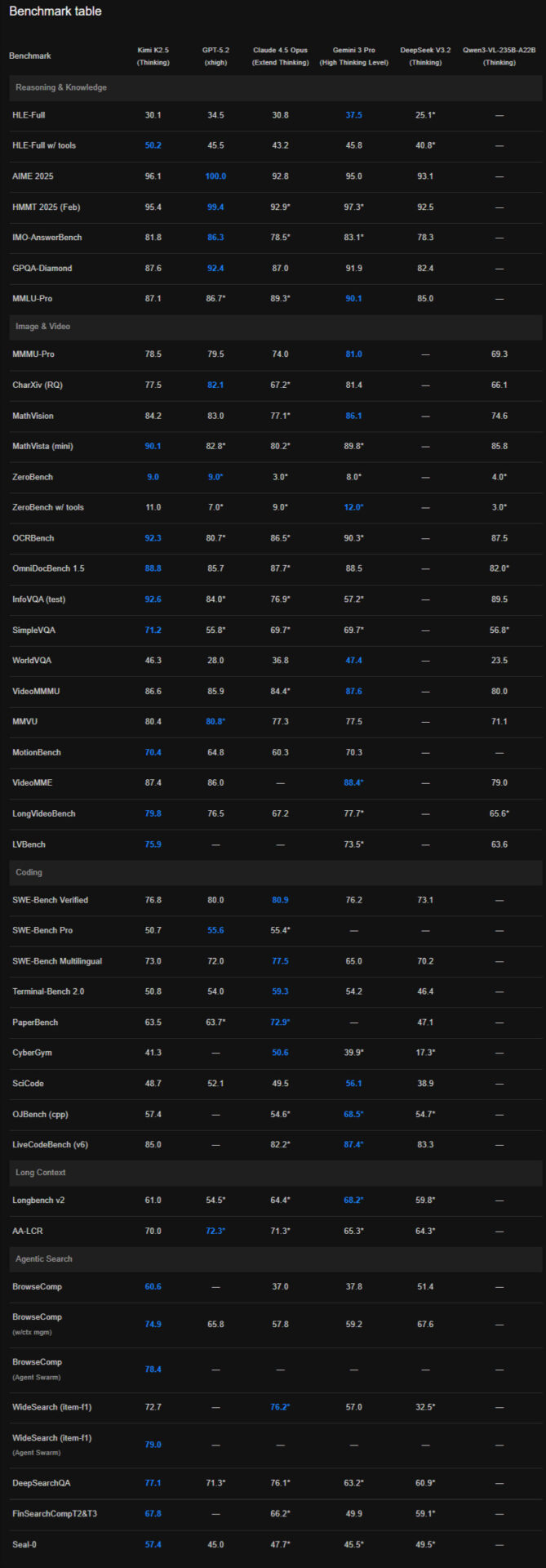
Benchmarks and Comparative Performance
Comparative evaluations place Kimi K2.5 among the top models for certain categories:
| Benchmark | Kimi K2.5 | Competitor Models |
| HLE Full (agentic reasoning) | ~50.2% | Claude Opus 4.5 ~32.0%, GPT-5.2 ~41.7% |
| SWE-Bench Verified (coding) | ~76.8% | Claude lower, GPT lower |
| VideoMMU (multimodal) | ~86.6% | Many models lower |
| BrowseComp Swarm | 78.4% in swarm vs ~74.9 standard |
These results underline that K2.5 excels in agentic search, multimodal reasoning and parallel task execution compared with some leading proprietary models.
It’s important to note that benchmarking conditions vary and real-world performance depends on task specifics, model tuning and context usage.
Open-Source Accessibility and Deployment
Kimi K2.5 is released as a fully open-weight model, meaning developers and organizations can:
- Self-host in local or private environments
- Customize and fine-tune for specific domains
- Integrate with existing infrastructure without vendor lock-in
Such open-source freedom makes K2.5 more attractive to entrepreneurs and researchers needing more control over data privacy, custom workflows, and compliance.
Quantization support allows deployment on commodity hardware in various configurations, though high-performance tasks and large swarms still get several benefits from enterprise GPUs.
Limitations and Considerations
While K2.5 comes with impressive capabilities, it is also worth analyzing some critical limitations:
- Real-world production case studies are often limited at launch; therefore, long-term reliability is still emerging
- Agent Swarm remains in beta on some of the core platforms. This means that production quality stabilities vary.
- Deploying a trillion-parameter MoE mobile may need significant hardware resources, which limits edge and mobile uses.
These factors showcase that while K2.5 is more powerful, organizations should plan pilot deployment and thorough testing before adopting it for a complex workflow.
Conclusion
Kimi K2.5 is a big step forward in open-source artificial intelligence. By combining native multimodal reasoning, agentic swarm execution, extensive contextual capacity and useful means of productivity, it is one of the most elaborate models accessible outside proprietary ecosystems.
Developers and organizations needing powerful, flexible and extensible artificial intelligence that can handle complex tasks on the fly, from visual coding to large-scale research synthesis capabilities, K2.5 is one of the most compelling ones in 2026. Nevertheless, careful evaluation and phased adoption are also necessary to gain most of its potential when integrated into production workflows.
FAQs
What makes Kimi K2.5 different from other open-source AI models?
K2.5 integrates native multimodal vision and language reasoning with an agent swarm architecture that can coordinate up to 100 parallel sub-agents, improving speed and performance on complex tasks.
Is Kimi K2.5 truly open source?
Yes. K2.5 is an open-weight model that developers can host, customize and fine-tune without vendor lock-in.
Can K2.5 handle large documents or long codebases?
Yes. Its 256K token context window allows processing of long documents, codebases and complex workflows without fragmenting context.
Does K2.5 work with images and video?
Yes. Native multimodal training lets K2.5 reason over images and video directly, enabling visual coding and debugging workflows.
What industries benefit most from K2.5?
Software engineering, design automation, research analysis, business productivity automation and multimodal content workflows all benefit significantly.
Is Agent Swarm reliable for production?
Agent Swarm shows strong parallel performance, but because it is in early stages and beta in some cases, organizations should conduct pilot evaluations before full production adoption.
In which languages is Kimi k2.5 proficient?
While it has a world-class mastery of both Chinese and English, Kimi k2.5 is highly proficient in over 20 languages and dozens of programming languages, including Python, C++, Java and Rust.
What is the maximum context window for Kimi k2.5?
Kimi k2.5 supports a context window of up to 2 million tokens. This allows it to process roughly 1.5 million words or several hours of video/audio data in a single prompt.
Is Kimi k2.5 free to use?
Moonshot AI offers a consumer-facing version of Kimi that is free to use with certain daily limits. For professional developers, access is provided through a tiered API pricing model based on token usage.
How does Kimi k2.5 handle data privacy?
Moonshot AI states that it adheres to stringent data protection standards. However, enterprise users are encouraged to use the API versions that typically offer more robust data-handling agreements regarding the training of future models.
Can Kimi k2.5 generate images?
Kimi k2.5 is primarily a multimodal understanding and text/code generation model. While it can analyze and interpret images with high precision, its primary strength is not in “text-to-image” generation like Midjourney or DALL-E 3.
In which languages is Kimi k2.5 proficient?
While it has a world-class mastery of both Chinese and English, Kimi k2.5 is highly proficient in over 20 languages and dozens of programming languages including Python, C++, Java and Rust.
How do I access the Kimi k2.5 API?
Developers can sign up through the Moonshot AI Open Platform. Once an account is created, they can generate API keys to integrate Kimi k2.5 into their own application.